This is the second of a sequence of two posts on sketching, which I’m doing on the occasion of my new paper on the numerical stability of the iterative sketching method. For more on what sketching is and how it can be used to solve computational problems, I encourage you to check out the first post.
The goals of this post are more narrow. I seek to answer the question:
Which sketching matrix should I use?
To cut to the chase, my answer to this question is:
Sparse sign embeddings are a sensible default for sketching.
There are certainly cases when sparse sign embeddings are not the best type of sketch to use, but I hope to convince you that they’re a good sketching matrix to use for most purposes.
Experiments
Let’s start things off with some numerical experiments.1Code for all numerical experiments can be found on the blogpost branch of the Github for my recent paper. We’ll compare three types of sketching matrices: Gaussian embeddings, a subsampled randomized trigonometric transform (SRTT), and sparse sign embeddings. See the last post for descriptions of these sketching matrices. I’ll discuss a few additional types of sketching matrices that require more discussion at the end of this post.
Recall that a sketching matrix  seeks to compress a high-dimensional matrix
seeks to compress a high-dimensional matrix  or vector
or vector  to a lower-dimensional sketched matrix
to a lower-dimensional sketched matrix  or vector
or vector  . The quality of a sketching matrix for a matrix
. The quality of a sketching matrix for a matrix  is measured by its distortion
is measured by its distortion  , defined to be the smallest number
, defined to be the smallest number  such that
such that
![\[(1-\varepsilon) \norm{x} \le \norm{Sx} \le (1+\varepsilon) \norm{x} \quad \text{for every } x \in \operatorname{col}(A).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-06811a2d05bdccddd7b3c3079ed47729_l3.png "Rendered by QuickLaTeX.com")
 denotes the column space of the matrix .
denotes the column space of the matrix .
Timing
We begin with timing test. We will measure three different times for each embedding:
- Construction. The time required to generate the sketching matrix
 .
. - Vector apply. The time to apply the sketch to a single vector.
- Matrix apply. The time to apply the sketch to an
 matrix.
matrix.
We will test with input dimension  (one million) and output dimension
(one million) and output dimension  . For the SRTT, we use the discrete cosine transform as our trigonometric transform. For the sparse sign embedding, we use a sparsity parameter
. For the SRTT, we use the discrete cosine transform as our trigonometric transform. For the sparse sign embedding, we use a sparsity parameter  .
.
Here are the results (timings averaged over 20 trials):
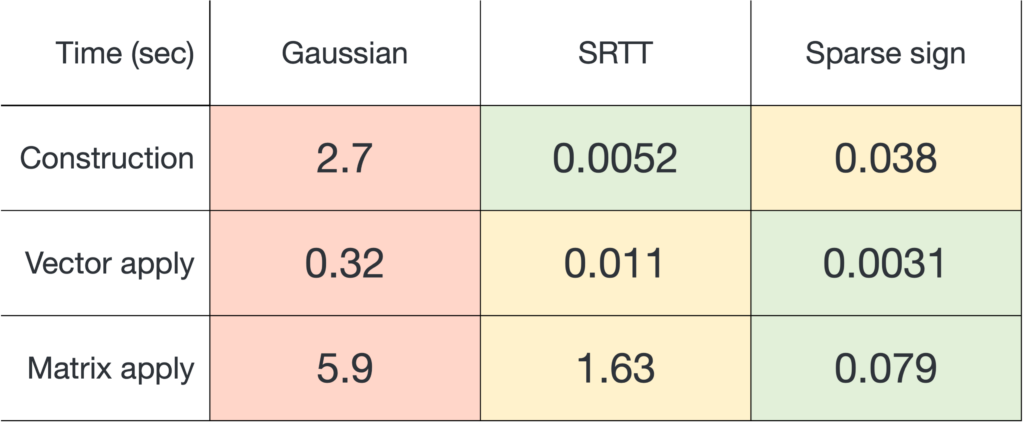
Our conclusions are as follows:
- Sparse sign embeddings are definitively the fastest to apply, being 3–20× faster than the SRTT and 74–100× faster than Gaussian embeddings.
- Sparse sign embeddings are modestly slower to construct than the SRTT, but much faster to construct than Gaussian embeddings.
Overall, the conclusion is that sparse sign embeddings are the fastest sketching matrices by a wide margin: For an “end-to-end” workflow involving generating the sketching matrix  and applying it to a matrix
and applying it to a matrix  , sparse sign embeddings are 14× faster than SRTTs and 73× faster than Gaussian embeddings.2More timings are reported in Table 1 of this paper, which I credit for inspiring my enthusiasm for the sparse sign embedding l.
, sparse sign embeddings are 14× faster than SRTTs and 73× faster than Gaussian embeddings.2More timings are reported in Table 1 of this paper, which I credit for inspiring my enthusiasm for the sparse sign embedding l.
Distortion
Runtime is only one measure of the quality of a sketching matrix; we also must care about the distortion . Fortunately, for practical purposes, Gaussian embeddings, SRTTs, and sparse sign embeddings all tend to have similar distortions. Therefore, we are free to use the sparse sign embeddings, as they as typically are the fastest.
Consider the following test. We generate a sparse random test matrix of size  for
for  and
and  using the MATLAB sprand function; we set the sparsity level to 1%. We then compare the distortion of Gaussian embeddings, SRTTs, and sparse sign embeddings across a range of sketching dimensions
using the MATLAB sprand function; we set the sparsity level to 1%. We then compare the distortion of Gaussian embeddings, SRTTs, and sparse sign embeddings across a range of sketching dimensions  between 100 and 10,000. We report the distortion averaged over 100 trials. The theoretically predicted value
between 100 and 10,000. We report the distortion averaged over 100 trials. The theoretically predicted value  (equivalently,
(equivalently,  ) is shown as a dashed line.
) is shown as a dashed line.
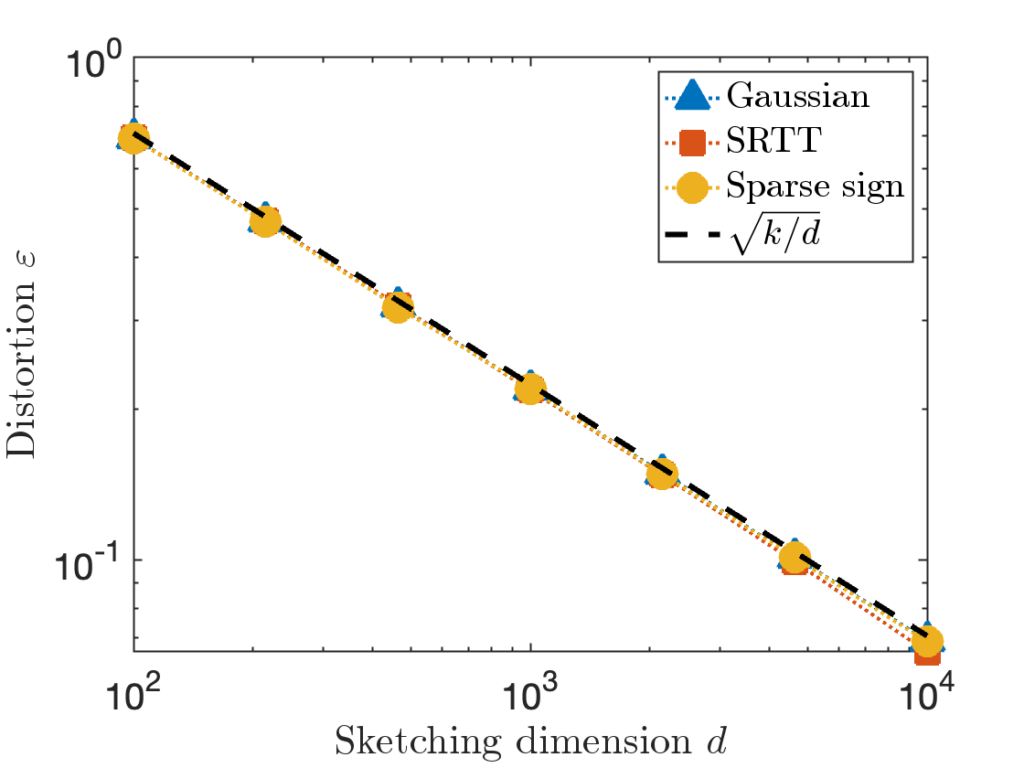
To me, I find these results remarkable. All three embeddings exhibit essentially the same distortion parameter predicted by the Gaussian theory.
It would be premature to declare success having only tested on one type of test matrix . Consider the following four test matrices:
- Sparse: The test matrix from above.
- Dense:
 is taken to be a matrix with independent standard Gaussian random values.
is taken to be a matrix with independent standard Gaussian random values. - Khatri–Rao:
 is taken to be the Khatri–Rao product of three Haar random orthogonal matrices.
is taken to be the Khatri–Rao product of three Haar random orthogonal matrices. - Identity:
 is taken to be the
is taken to be the  identity matrix stacked onto a
identity matrix stacked onto a  matrix of zeros.
matrix of zeros.
The performance of sparse sign embeddings (again with sparsity parameter ) is shown below:
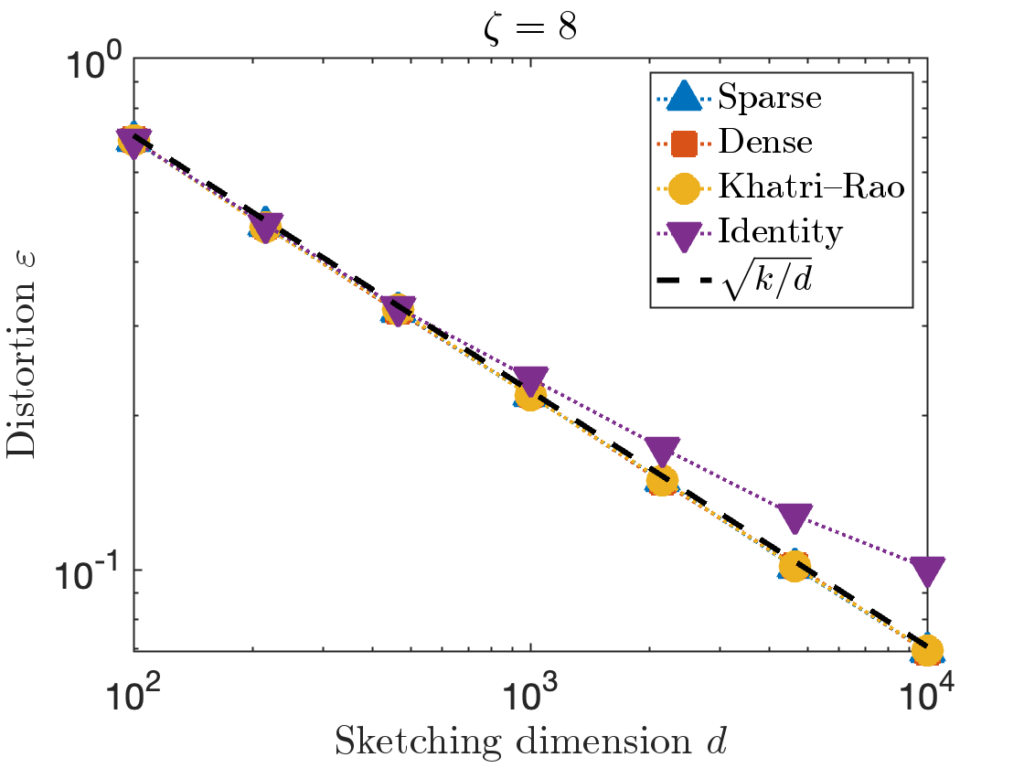
We see that for the first three test matrices, the performance closely follows the expected value  . However, for the last test matrix “Identity”, we see the distortion begins to slightly exceed this predicted distortion for
. However, for the last test matrix “Identity”, we see the distortion begins to slightly exceed this predicted distortion for  .
.
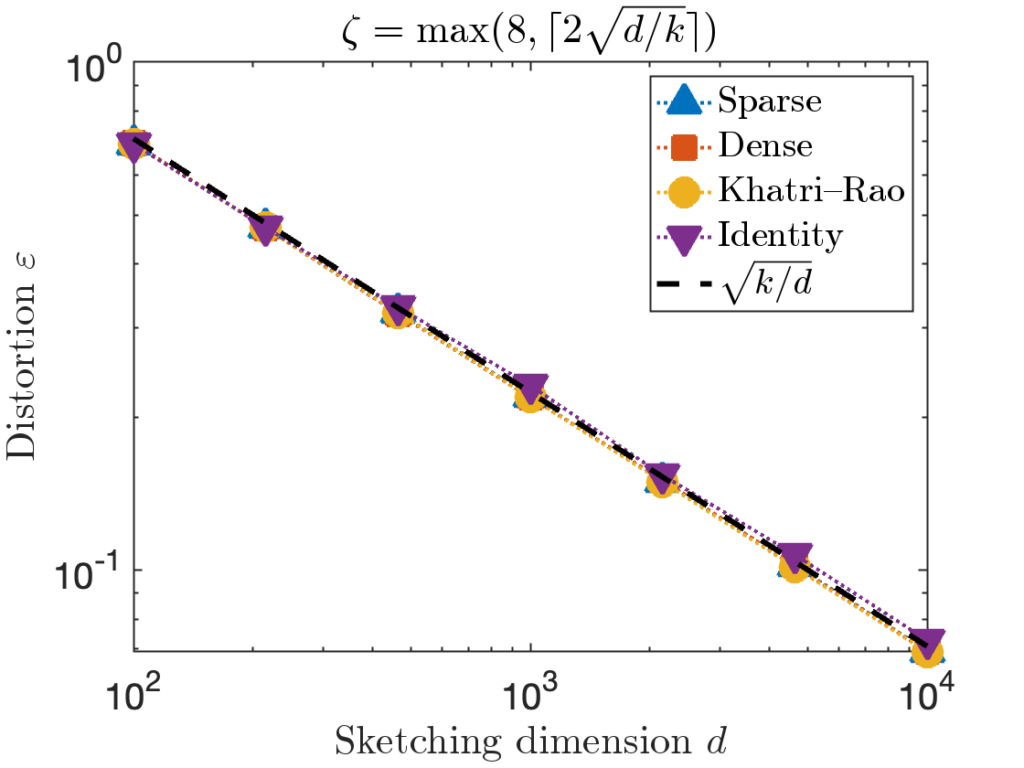
To improve sparse sign embeddings for higher values of  , we can increase the value of the sparsity parameter
, we can increase the value of the sparsity parameter  . We recommend
. We recommend
![\[\zeta = \max \left( 8 , \left\lceil 2\sqrt{\frac{d}{k}} \right\rceil \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5f1ebe7695d9918399b0f97b628fcce1_l3.png "Rendered by QuickLaTeX.com")
for all four test matrices:
Conclusion
Implemented appropriately (see below), sparse sign embeddings can be faster than other sketching matrices by a wide margin. The parameter choice is enough to ensure the distortion closely tracks for most test matrices. For the toughest test matrices, a slightly larger sparsity parameter  can be necessary to achieve the optimal distortion.
can be necessary to achieve the optimal distortion.
While these tests are far from comprehensive, they are consistent with the uniformly positive results for sparse sign embeddings reported in the literature. We believe that this evidence supports the argument that sparse sign embeddings are a sensible default sketching matrix for most purposes.
Sparse Sign Embeddings: Theory and Practice
Given the highly appealing performance characteristics of sparse sign embeddings, it is worth saying a few more words about these embeddings and how they perform in both theory and practice.
Recall that a sparse sign embedding is a random matrix of the form
![\[S = \frac{1}{\sqrt{\zeta}} \begin{bmatrix} s_1 & \cdots & s_n \end{bmatrix}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4871e53b2bb59ad11946f2d1eafc66f7_l3.png "Rendered by QuickLaTeX.com")
 is an independent and randomly generated to contain exactly nonzero entries in uniformly random positions. The value of each nonzero entry of is chosen to be either
is an independent and randomly generated to contain exactly nonzero entries in uniformly random positions. The value of each nonzero entry of is chosen to be either  or
or  with 50/50 odds.
with 50/50 odds.
Parameter Choices
The goal of sketching is to reduce vectors of length  to a smaller dimension . For linear algebra applications, we typically want to preserve all vectors in the column space of a matrix up to distortion :
to a smaller dimension . For linear algebra applications, we typically want to preserve all vectors in the column space of a matrix up to distortion :
![\[(1-\varepsilon) \norm{x} \le \norm{Sx} \le (1+\varepsilon) \norm{x} \quad \text{for all }x \in \operatorname{col}(A).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-41fd14292c1c85cd318dde801a75e1bd_l3.png "Rendered by QuickLaTeX.com")
Given a dimension
and a target distortion
Based on the experiments above (and other testing reported in the literature), we recommend the following parameter choices in practice:
![\[d = \frac{k}{\varepsilon^2} \quad \text{and} \quad \zeta = \max\left(8,\frac{2}{\varepsilon}\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ed85cec8dadffec7c7a3b4e099d6637d_l3.png "Rendered by QuickLaTeX.com")
is advocated by Tropp, Yurtever, Udell, and Cevher; they mention experimenting with parameter values as small as  . The value
. The value  has demonstrated deficiencies and should almost always be avoided (see below). The scaling
has demonstrated deficiencies and should almost always be avoided (see below). The scaling  is derived from the analysis of Gaussian embeddings. As Martinsson and Tropp argue, the analysis of Gaussian embeddings tends to be reasonably descriptive of other well-designed random embeddings.
is derived from the analysis of Gaussian embeddings. As Martinsson and Tropp argue, the analysis of Gaussian embeddings tends to be reasonably descriptive of other well-designed random embeddings.
The best-known theoretical analysis, due to Cohen, suggests more cautious parameter setting for sparse sign embeddings:
![\[d = \mathcal{O} \left( \frac{k \log k}{\varepsilon^2} \right) \quad \text{and} \quad \zeta = \mathcal{O}\left( \frac{\log k}{\varepsilon} \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4fb6d0d60c85bc8a60d95bb0a19e63d6_l3.png "Rendered by QuickLaTeX.com")
 factor and the lack of explicit constants in the O-notation.
factor and the lack of explicit constants in the O-notation.
Implementation
For good performance, it is imperative to store using either a purpose-built data structure or a sparse matrix format (such as a MATLAB sparse matrix or scipy sparse array).
If a sparse matrix library is unavailable, then either pursue a dedicated implementation or use a different type of embedding; sparse sign embeddings are just as slow as Gaussian embeddings if they are stored in an ordinary non-sparse matrix format!
Even with a sparse matrix format, it can require care to generate and populate the random entries of the matrix . Here, for instance, is a simple function for generating a sparse sign matrix in MATLAB:
function S = sparsesign_slow(d,n,zeta)
cols = kron((1:n)',ones(zeta,1)); % zeta nonzeros per column
vals = 2*randi(2,n*zeta,1) - 3; % uniform random +/-1 values
rows = zeros(n*zeta,1);
for i = 1:n
rows((i-1)*zeta+1:i*zeta) = randsample(d,zeta);
end
S = sparse(rows, cols, vals / sqrt(zeta), d, n);
endHere, we specify the rows, columns, and values of the nonzero entries before assembling them into a sparse matrix using the MATLAB sparse command. Since there are exactly nonzeros per column, the column indices are easy to generate. The values are uniformly  and can also be generated using a single line. The real challenge to generating sparse sign embeddings in MATLAB is the row indices, since each batch of row indices much be chosen uniformly at random between
and can also be generated using a single line. The real challenge to generating sparse sign embeddings in MATLAB is the row indices, since each batch of row indices much be chosen uniformly at random between  and without replacement. This is accomplished in the above code by a for loop, generating row indices at a time using the slow randsample function.
and without replacement. This is accomplished in the above code by a for loop, generating row indices at a time using the slow randsample function.
As its name suggests, the sparsesign_slow is very slow. To generate a  sparse sign embedding with sparsity requires 53 seconds!
sparse sign embedding with sparsity requires 53 seconds!
Fortunately, we can do (much) better. By rewriting the code in C and directly generating the sparse matrix in the CSC format MATLAB uses, generating this same 200 by 10 million sparse sign embedding takes just 0.4 seconds, a speedup of 130× over the slow MATLAB code. A C implementation of the sparse sign embedding that can be used in MATLAB using the MEX interface can be found in this file in the Github repo for my recent paper.
Other Sketching Matrices
Let’s leave off the discussion by mentioning other types of sketching matrices not considered in the empirical comparison above.
Coordinate Sampling
Another family of sketching matrices that we haven’t talked about are coordinate sampling sketches. A coordinate sampling sketch consists of indices  and weights
and weights  . To apply , we sample the indices
. To apply , we sample the indices  and reweight them using the weights:
and reweight them using the weights:
![\[b \in \real^n \longmapsto Sb = (w_1 b_{i_1},\ldots,w_db_{i_d}) \in \real^d.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-712b97fc6f6efb9bf9a40dac2a652f5c_l3.png "Rendered by QuickLaTeX.com")
Coordinate sampling is very appealing: To apply to a matrix or vector requires no matrix multiplication of trigonometric transforms, just picking out some entries or rows and rescaling them.
In order for coordinate sampling to be effective, we need to pick the right indices. Below, we compare two coordinate sampling sketching approaches, uniform sampling and leverage score sampling (both with replacement), to the sparse sign embedding with the suggested parameter setting  for the hard “Identity” test matrix used above.
for the hard “Identity” test matrix used above.
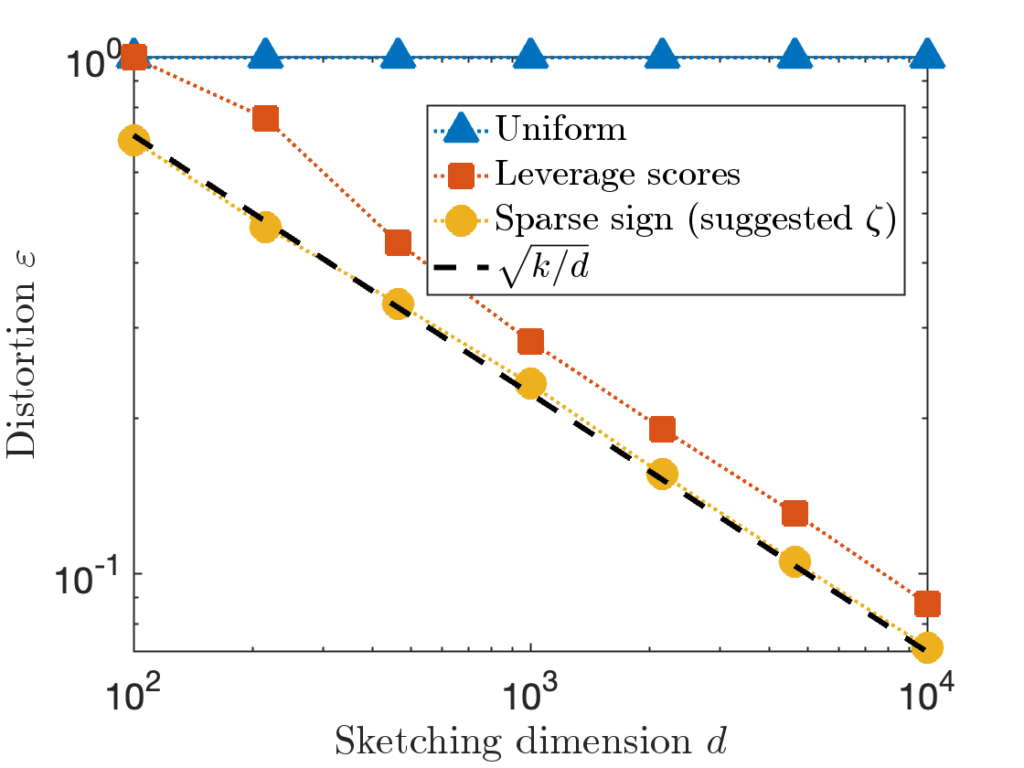
We see right away that the uniform sampling fails dramatically on this problem. That’s to be expected. All but 50 of 100,000 rows of are zero, so picking rows uniformly at random will give nonsense with very high probability. Uniform sampling can work well for matrices which are “incoherent”, with all rows of being of “similar importance”.
Conclusion (Uniform sampling). Uniform sampling is a risky method; it works excellently for some problems, but fails spectacularly for others. Use only with caution!
The ridge leverage score sampling method is more interesting. Unlike all the other sketches we’ve discussed in this post, ridge leverage score sampling is data-dependent. First, it computes a leverage score  for each row of and then samples rows with probabilities proportional to these scores. For high enough values of , ridge leverage score sampling performs slightly (but only slightly) worse than the characteristic scaling we expect for an oblivious subspace embedding.
for each row of and then samples rows with probabilities proportional to these scores. For high enough values of , ridge leverage score sampling performs slightly (but only slightly) worse than the characteristic scaling we expect for an oblivious subspace embedding.
Ultimately, leverage score sampling has two disadvantages when compared with oblivious sketching matrices:
- Higher distortion, higher variance. The distortion of a leverage score sketch is higher on average, and more variable, than an oblivious sketch, which achieve very consistent performance.
- Computing the leverage scores. In order to implement this sketch, the leverage scores have to first be computed or estimated. This is a nontrivial algorithmic problem; the most direct way of computing the leverage scores requires a QR decomposition at
 cost, much higher than other types of sketches.
cost, much higher than other types of sketches.
There are settings when coordinate sampling methods, such as leverage scores, are well-justified:
- Structured matrices. For some matrices , the leverage scores might be very cheap to compute or approximate. In such cases, coordinate sampling can be faster than oblivious sketching.
- “Active learning”. For some problems, each entry of the vector
 or row of the matrix may be expensive to generate. In this case, coordinate sampling has the distinct advantage that computing or only requires generating the entries of or rows of for the randomly selected indices .
or row of the matrix may be expensive to generate. In this case, coordinate sampling has the distinct advantage that computing or only requires generating the entries of or rows of for the randomly selected indices .
Ultimately, oblivious sketching and coordinate sampling both have their place as tools in the computational toolkit. For the reasons described above, I believe that oblivious sketching should usually be preferred to coordinate sampling in the absence of a special reason to prefer the latter.
Tensor Random Embeddings
There are a number of sketching matrices with tensor structure; see here for a survey. These types of sketching matrices are very well-suited to tensor computations. If tensor structure is present in your application, I would put these types of sketches at the top of my list for consideration.
CountSketch
The CountSketch sketching matrix is the case of the sparse sign embedding. CountSketch has serious deficiencies, and should only be used in practice with extreme care.
Consider the “Identity” test matrix from above but with parameter  , and compare the distortion of CountSketch to the sparse sign embedding with parameters
, and compare the distortion of CountSketch to the sparse sign embedding with parameters  :
:
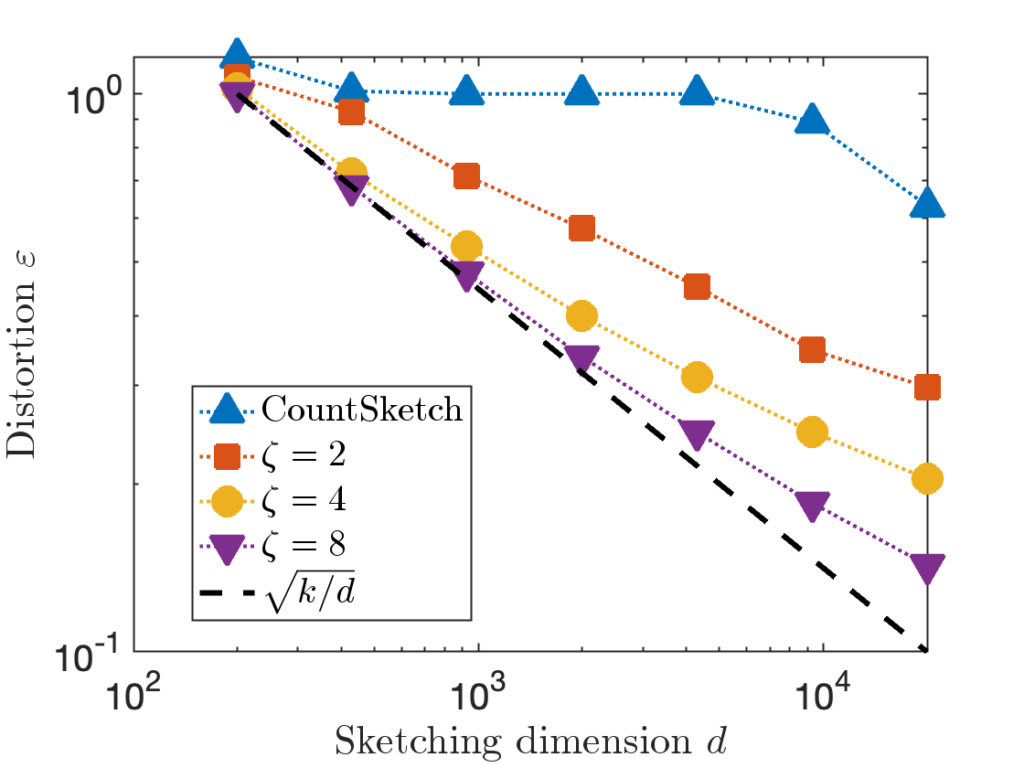
We see that the distortion of the CountSketch remains persistently high at 100% until the sketching dimension is taken  , 20× higher than .
, 20× higher than .
CountSketch is bad because it requires to be proportional to  in order to achieve distortion . For all of the other sketching matrices we’ve considered, we’ve only required to be proportional to
in order to achieve distortion . For all of the other sketching matrices we’ve considered, we’ve only required to be proportional to  (or perhaps
(or perhaps  ). This difference between
). This difference between  for CountSketch and
for CountSketch and  for other sketching matrices is a at the root of CountSketch’s woefully bad performance on some inputs.3Here, the symbol
for other sketching matrices is a at the root of CountSketch’s woefully bad performance on some inputs.3Here, the symbol  is an informal symbol meaning “proportional to”.
is an informal symbol meaning “proportional to”.
The fact that CountSketch requires is simple to show. It’s basically a variant on the famous birthday problem. We include a discussion at the end of this post.4In fact, any oblivious sketching matrix with only 1 nonzero entry per column must have  . This is Theorem 16 in the following paper.
. This is Theorem 16 in the following paper.
There are ways of fixing the CountSketch. For instance, we can use a composite sketch  , where
, where  is a CountSketch of size
is a CountSketch of size  and
and  is a Gaussian sketching matrix of size
is a Gaussian sketching matrix of size  .5This construction is from this paper. For most applications, however, salvaging CountSketch doesn’t seem worth it; sparse sign embeddings with even nonzeros per column are already way more effective and reliable than a plain CountSketch.
.5This construction is from this paper. For most applications, however, salvaging CountSketch doesn’t seem worth it; sparse sign embeddings with even nonzeros per column are already way more effective and reliable than a plain CountSketch.
Conclusion
By now, sketching is quite a big field, with dozens of different proposed constructions for sketching matrices. So which should you use? For most use cases, sparse sign embeddings are a good choice; they are fast to construct and apply and offer uniformly good distortion across a range of matrices.
Let
is a CountSketch matrix with output dimension
, then the distortion of
with high probability.
Let’s see why. By the structure of the matrix , has the form
![\[SA = \begin{bmatrix} s_1 & \cdots & s_k \end{bmatrix}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-82c7ea0e5c52b6bd9bdb389f3d3f92d7_l3.png "Rendered by QuickLaTeX.com")
 has a single
has a single  in a uniformly random location
in a uniformly random location  .
.
Suppose that the indices  are not all different from each other, say
are not all different from each other, say  . Set
. Set  , where
, where  is the standard basis vector with in position
is the standard basis vector with in position  and zeros elsewhere. Then,
and zeros elsewhere. Then,  but
but  . Thus, for the distortion relation
. Thus, for the distortion relation
![\[(1-\varepsilon) \norm{x} =(1-\varepsilon)\sqrt{2} \le 0 = \norm{(SA)x}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b08feebb30829a0e73b02188eba6f901_l3.png "Rendered by QuickLaTeX.com")
 . Thus,
. Thus, ![\[\prob \{ \varepsilon \ge 1 \} \ge \prob \{ j_1,\ldots,j_k \text{ are not distinct} \}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-12fa7b716b97c7e9482f4f6327bd4728_l3.png "Rendered by QuickLaTeX.com")
For a moment, let’s put aside our analysis of the CountSketch, and turn our attention to a famous puzzle, known as the birthday problem:
How many people have to be in a room before there’s at least a 50% chance that two people share the same birthday?
The counterintuitive or “paradoxical” answer: 23. This is much smaller than many people’s intuition, as there are 365 possible birthdays and 23 is much smaller than 365.
The reason for this surprising result is that, in a room of 23 people, there are  pairs of people. Each pair of people has a
pairs of people. Each pair of people has a  chance of sharing a birthday, so the expected number of birthdays in a room of 23 people is
chance of sharing a birthday, so the expected number of birthdays in a room of 23 people is  . Since are 0.69 birthdays shared on average in a room of 23 people, it is perhaps less surprising that 23 is the critical number at which the chance of two people sharing a birthday exceeds 50%.
. Since are 0.69 birthdays shared on average in a room of 23 people, it is perhaps less surprising that 23 is the critical number at which the chance of two people sharing a birthday exceeds 50%.
Hopefully, the similarity between the birthday problem and CountSketch is becoming clear. Each pair of indices  and
and  in CountSketch have a
in CountSketch have a  chance of being the same. There are
chance of being the same. There are  pairs of indices, so the expected number of equal indices is
pairs of indices, so the expected number of equal indices is  . Thus, we should anticipate
. Thus, we should anticipate  is required to ensure that are distinct with high probability.
is required to ensure that are distinct with high probability.
Let’s calculate things out a bit more precisely. First, realize that
![\[\prob \{ j_1,\ldots,j_k \text{ are not distinct} \} = 1 - \prob \{ j_1,\ldots,j_k \text{ are distinct} \}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-338a38501a565185b794f8ed03803c9a_l3.png "Rendered by QuickLaTeX.com")
are distinct, imagine introducing each one at a time. Assuming that  are all distinct, the probability
are all distinct, the probability  are distinct is just the probability that does not take any of the
are distinct is just the probability that does not take any of the  values . This probability is
values . This probability is ![\[\prob\{ j_1,\ldots,j_i \text{ are distinct} \mid j_1,\ldots,j_{i-1} \text{ are distinct}\} = 1 - \frac{i-1}{d}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b474f00c44e53b7c3c398d56121e1ac3_l3.png "Rendered by QuickLaTeX.com")
![\[\prob \{ j_1,\ldots,j_k \text{ are distinct} \} = \prod_{i=1}^k \left(1 - \frac{i-1}{d} \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7dd28281f8dbed8b3a1452a21e7410c8_l3.png "Rendered by QuickLaTeX.com")
 for every
for every  , obtaining
, obtaining ![\[\mathbb{P} \{ j_1,\ldots,j_k \text{ are distinct} \} \le \prod_{i=0}^{k-1} \exp\left(-\frac{i}{d}\right) = \exp \left( -\frac{1}{d}\sum_{i=0}^{k-1} i \right) = \exp\left(-\frac{k(k-1)}{2d}\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8d9d4c7d12af0fd89e53ca261c5df287_l3.png "Rendered by QuickLaTeX.com")
![\[\prob \{ \varepsilon \ge 1 \} \ge 1-\prob \{ j_1,\ldots,j_k \text{ are distinct} \\}\ge 1-\exp\left(-\frac{k(k-1)}{2d}\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-144cfc73d778c4f9ed7442f5a6610e5e_l3.png "Rendered by QuickLaTeX.com")
![\[\prob\{\varepsilon \ge 1\} \ge \frac{1}{2} \quad \text{if} \quad d \le \frac{k(k-1)}{2\ln 2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e11567078a415b79b06a8e5e6f0b1600_l3.png "Rendered by QuickLaTeX.com")
4 thoughts on “Which Sketch Should I Use?”