I am delighted to share that me, Joel A. Tropp, and Robert J. Webber‘s paper XTrace: Making the Most of Every Sample in Stochastic Trace Estimation has recently been released as a preprint on arXiv. In it, we consider the implicit trace estimation problem:
Implicit trace estimation problem: Given access to a square matrix  via the matrix–vector product operation
via the matrix–vector product operation  , estimate its trace
, estimate its trace  .
.
Algorithms for this task have many uses such as log-determinant computations in machine learning, partition function calculations in statistical physics, and generalized cross validation for smoothing splines. I described another application to counting triangles in a large network in a previous blog post.
Our paper presents new trace estimators XTrace and XNysTrace which are highly efficient, producing accurate trace approximations using a small budget of matrix–vector products. In addition, these algorithms are fast to run and are supported by theoretical results which explain their excellent performance. I really hope that you will check out the paper to learn more about these estimators!
For the rest of this post, I’m going to talk about the most basic stochastic trace estimation algorithm, the Girard–Hutchinson estimator. This seemingly simple algorithm exhibits a number of nuances and forms the backbone for more sophisticated trace estimates such as Hutch++, Nyström++, XTrace, and XNysTrace. Toward the end, this blog post will be fairly mathematical, but I hope that the beginning will be fairly accessible to all.
Girard–Hutchinson Estimator: The Basics
The Girard–Hutchinson estimator for the trace of a square matrix is
(1) ![\[\hat{\tr} = \frac{1}{m} \sum_{i=1}^m \omega_i^* A \omega_i. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a287886ee24c9ab99dfe35b6cdae83cf_l3.png "Rendered by QuickLaTeX.com")
Here,  are random vectors, usually chosen to be statistically independent, and
are random vectors, usually chosen to be statistically independent, and  denotes the conjugate transpose of a vector or matrix. The Girard–Hutchinson estimator only depends on the matrix through the matrix–vector products
denotes the conjugate transpose of a vector or matrix. The Girard–Hutchinson estimator only depends on the matrix through the matrix–vector products  .
.
Unbiasedness
Provided the random vectors are isotropic
(2) ![\[\mathbb{E} [\omega_i\omega_i^*] = I, \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-74bb76367ad1408bd538d049774cf990_l3.png "Rendered by QuickLaTeX.com")
the Girard–Hutchinson estimator is unbiased:
(3) ![\[\mathbb{E} [\hat{\tr}] = \tr A.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f6407c7a741003cc20780e72d050cb56_l3.png "Rendered by QuickLaTeX.com")
Let us confirm this claim in some detail. First, we use linearity of expectation to evaluate
(4) ![\[\mathbb{E} [\hat{\tr}] = \mathbb{E} \left[ \frac{1}{m} \sum_{i=1}^m \omega_i^*A\omega_i \right] = \frac{1}{m} \sum_{i=1}^m \mathbb{E} \left[ \omega_i^* A \omega_i\right]. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-52eebd003a597cac5b2c69f7b6e537e8_l3.png "Rendered by QuickLaTeX.com")
Therefore, to prove that ![\mathbb{E} [\hat{\tr}] = \tr A](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-96f71a1b054ffed9e316cf9cb7a16c5c_l3.png "Rendered by QuickLaTeX.com") , it is sufficient to prove that
, it is sufficient to prove that ![\mathbb{E} \left[\omega_i^*A\omega_i\right] = \tr A](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-120169dca277175c51f09b6f320cf5fa_l3.png "Rendered by QuickLaTeX.com") for each
for each  .
.
When working with traces, there are two tricks that solve 90% of derivations. The first trick is that, if we view a number as a  matrix, then a number equals its trace,
matrix, then a number equals its trace,  . The second trick is the cyclic property: For a
. The second trick is the cyclic property: For a  matrix
matrix  and a
and a  matrix
matrix  , we have
, we have  . The cyclic property should be handled with care when one works with a product of three or more matrices. For instance, we have
. The cyclic property should be handled with care when one works with a product of three or more matrices. For instance, we have
![\[\tr[BCD] = \tr[(BC)D] = \tr[D(BC)] = \tr[DBC].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-cc1cd4920a2431e93b5453b5373999e3_l3.png "Rendered by QuickLaTeX.com")
However,
![\[\tr [BCD] \ne \tr[CBD] \quad \text{in general}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f563660fc58383a37ae7bedea16b2b9c_l3.png "Rendered by QuickLaTeX.com")
One should think of the matrix product  as beads on a closed loop of string. One can move the last bead
as beads on a closed loop of string. One can move the last bead  to the front of the other two,
to the front of the other two, ![\tr [BCD] = \tr[DBC]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7656627b133add21ab8765532def07d6_l3.png "Rendered by QuickLaTeX.com") , but not interchange two beads,
, but not interchange two beads, ![\tr[BCD] \ne \tr[CBD]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0f43e4f72510a69b596f7b9f7504dd58_l3.png "Rendered by QuickLaTeX.com") .
.
With this trick in hand, let’s return to proving that for every . Apply our two tricks:
![\[\mathbb{E} \left[\omega_i^*A\omega_i\right] = \mathbb{E} \tr \left[\omega_i^*A\omega_i\right] = \mathbb{E} \tr \left[A\omega_i\omega_i^*\right].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b1bb373766e64179bc0635f058a07f3f_l3.png "Rendered by QuickLaTeX.com")
The expectation is a linear operation and the matrix is non-random, so we can bring the expectation into the trace as
![\[\mathbb{E} \left[\omega_i^*A\omega_i\right] = \mathbb{E} \tr \left[A\omega_i\omega_i^*\right] = \tr(A \mathbb{E}[\omega_i\omega_i^*] ).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1d10f835c99efab005f0ad12cdb5647b_l3.png "Rendered by QuickLaTeX.com")
Invoke the isotropy condition (2) and conclude:
![\[\mathbb{E} \left[\omega_i^*A\omega_i\right] = \tr(A \mathbb{E}[\omega_i\omega_i^*] ) = \tr(A\cdot I) = \tr A.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b51781498146df3547c1503e451ad682_l3.png "Rendered by QuickLaTeX.com")
Plugging this into (4) confirms the unbiasedness claim (3).
Variance
Continue to assume that the  ‘s are isotropic (3) and now assume that are independent. By independence, the variance can be written as
‘s are isotropic (3) and now assume that are independent. By independence, the variance can be written as
![\[\Var(\hat{\tr}) = \frac{1}{m^2} \sum_{i=1}^m \Var(\omega_i^*A\omega_i).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d9398dc43178ba9bb72aead0214e77c8_l3.png "Rendered by QuickLaTeX.com")
Assuming that are identically distributed  , we then get
, we then get
![\[\Var(\hat{\tr}) = \frac{1}{m} \Var(\omega^*A\omega).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4501a18842234362f8f99d523c7c723e_l3.png "Rendered by QuickLaTeX.com")
The variance decreases like  , which is characteristic of Monte Carlo-type algorithms. Since
, which is characteristic of Monte Carlo-type algorithms. Since  is unbiased (i.e, (3)), this means that the mean square error decays like so the average error (more precisely root-mean-square error) decays like
is unbiased (i.e, (3)), this means that the mean square error decays like so the average error (more precisely root-mean-square error) decays like
![\[\left| \hat{\tr} - \tr A \right| \lessapprox \frac{\mathrm{const}}{\sqrt{m}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c735791b8fe88d627bc2ebad8137fb1e_l3.png "Rendered by QuickLaTeX.com")
This type of convergence is very slow. If I want to decrease the error by a factor of  , I must do
, I must do  the work!
the work!
Variance-reduced trace estimators like Hutch++ and our new trace estimator XTrace improve the rate of convergence substantially. Even in the worst case, Hutch++ and XTrace reduce the variance at a rate  and (root-mean-square) error at rates :
and (root-mean-square) error at rates :
![\[\Var(\hat{\tr}_{\text{H++ or X}}) \le \frac{\mathrm{const}}{m^2},\quad \left| \hat{\tr}_{\text{H++ or X}} - \tr A \right| \lessapprox \frac{\mathrm{const}}{m}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-87438d87094d3df389400b5f7abee24a_l3.png "Rendered by QuickLaTeX.com")
For matrices with rapidly decreasing singular values, the variance and error can decrease much faster than this.
Variance Formulas
As the rate of convergence for the Girard–Hutchinson estimator is so slow, it is imperative to pick a distribution on test vectors  that makes the variance of the single–sample estimate
that makes the variance of the single–sample estimate  as low as possible. In this section, we will provide several explicit formulas for the variance of the Girard–Hutchinson estimator. Derivations of these formulas will appear at the end of this post. These variance formulas help illuminate the benefits and drawbacks of different test vector distributions.
as low as possible. In this section, we will provide several explicit formulas for the variance of the Girard–Hutchinson estimator. Derivations of these formulas will appear at the end of this post. These variance formulas help illuminate the benefits and drawbacks of different test vector distributions.
To express the formulas, we will need some notation. For a complex number  we use
we use  and
and  to denote the real and imaginary parts. The variance of a random complex number
to denote the real and imaginary parts. The variance of a random complex number  is
is
![\[\Var(z) := \mathbb{E} |z - \mathbb{E} z|^2 = \Var(\Re z) + \Var(\Im z).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8f636667a7dbbb3217896a962de1d28c_l3.png "Rendered by QuickLaTeX.com")
The Frobenius norm of a matrix is
![\[\left\|A\right\|_{\rm F}^2 = \sum_{i,j} |A_{ij}|^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e132e4b9029c41dbfb99cd0e588d8d70_l3.png "Rendered by QuickLaTeX.com")
If is real symmetric or complex Hermitian with (real) eigenvalues  , we have
, we have
(5) ![\[\left\|A\right\|_{\rm F}^2 = \sum_{i=1}^n \lambda_i^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-06b272e602552353c020f6399347c748_l3.png "Rendered by QuickLaTeX.com")
 denotes the ordinary transpose of and
denotes the ordinary transpose of and  denotes the conjugate transpose of .
denotes the conjugate transpose of .
Real-Valued Test Vectors
We first focus on real-valued test vectors . Since is real, we can use the ordinary transpose  rather than the conjugate transpose . Since
rather than the conjugate transpose . Since  is a number, it is equal to its own transpose:
is a number, it is equal to its own transpose:
![\[\omega^\top A \omega = (\omega^\top A \omega)^\top = \omega^\top A^\top \omega.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3d543dc0d4d64d3c28f0f291cd9c8e83_l3.png "Rendered by QuickLaTeX.com")
Therefore,
![\[\omega^\top A\omega = \frac{\omega^\top A \omega + \omega^\top A^\top \omega}{2} = \omega^\top \left( \frac{A + A^\top}{2} \right)\omega.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f1bbe4f0c983f73e2461b593b752f54a_l3.png "Rendered by QuickLaTeX.com")
The Girard–Hutchinson trace estimator applied to is the same as the Girard–Hutchinson estimator applied to the symmetric part of ,  .
.
For the following results, assume is symmetric,  .
.
- Real Gaussian: are independent standard normal random vectors.
![\[\Var(\omega^\top A\omega) = 2 \left\|A\right\|_{\rm F}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-091cf638fab943be5fd224acdb42668f_l3.png "Rendered by QuickLaTeX.com")
- Uniform signs (Rademachers): are independent random vectors with uniform
 coordinates.
coordinates. ![\[\Var(\omega^\top A \omega) = 2\sum_{i\ne j} |A_{ij}|^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-74621dad79cb3f06a8b70c661df4e01d_l3.png "Rendered by QuickLaTeX.com")
- Real sphere: Assume
 are uniformly distributed on the real sphere of radius
are uniformly distributed on the real sphere of radius  :
:  .
. ![\[\Var(\omega^\top A\omega) = \frac{2n}{n+2} \left( \left\|A\right\|_{\rm F}^2 - \frac{1}{n} |\tr A|^2 \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1e419b8da9b953a0b8b914df9e89f8c6_l3.png "Rendered by QuickLaTeX.com")
These formulas continue to hold for nonsymmetric by replacing by its symmetric part on the right-hand sides of these variance formulas.
Complex-Valued Test Vectors
We now move our focus to complex-valued test vectors . As a rule of thumb, one should typically expect that the variance for complex-valued test vectors applied to a real symmetric matrix is about half the natural real counterpart—e.g., for complex Gaussians, you get about half the variance than with real Gaussians.
A square complex matrix has a Cartesian decomposition
![\[A = A^{\rm H} + i A^{\rm SH}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d61da43cd6497ceefd2306aabb52ee67_l3.png "Rendered by QuickLaTeX.com")
where
![\[A^{\rm H} = \frac{A+A^*}{2} ,\quad A^{\rm SH} = \frac{A - A^*}{2i}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-dc287a49a59dca9421fdd2bef6be5334_l3.png "Rendered by QuickLaTeX.com")
denote the Hermitian and skew-Hermitian parts of . Similar to how the imaginary part of a complex number is real, the skew-Hermitian part of a complex matrix is Hermitian (and  is skew-Hermitian). Since
is skew-Hermitian). Since  and
and  are both Hermitian, we have
are both Hermitian, we have
![\[\Re(\omega^* A\omega) = \omega^* A^{\rm H} \omega, \quad \Im (\omega^* A \omega) = \omega^* A^{\rm SH} \omega.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6809a35cd06d92218ce8d597847f74bd_l3.png "Rendered by QuickLaTeX.com")
Consequently, the variance of  can be broken into Hermitian and skew-Hermitian parts:
can be broken into Hermitian and skew-Hermitian parts:
![\[\Var(\omega^* A\omega) = \Var(\omega^* A^{\rm H}\omega) + \Var(\omega^* A^{\rm SH}\omega).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e4658c38df479c5805dabd94b64cc0b3_l3.png "Rendered by QuickLaTeX.com")
For this reason, we will state the variance formulas only for Hermitian , with the formula for general following from the Cartesian decomposition.
For the following results, assume is Hermitian,  .
.
- Complex Gaussian: are independent standard complex random vectors, i.e., each has iid entries distributed as
 for
for  standard normal random variables.
standard normal random variables. ![\[\Var(\omega^* A\omega) = \left\|A\right\|_{\rm F}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1beb66e032d83431dac6f8e0d6655eec_l3.png "Rendered by QuickLaTeX.com")
- Uniform phases (Steinhauses): are independent random vectors whose entries are uniform on the complex unit circle
 .
. ![\[\Var(\omega^* A \omega) = \sum_{i\ne j} |A_{ij}|^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1cb0e8df66c34056cd350752070af17a_l3.png "Rendered by QuickLaTeX.com")
- Complex sphere: Assume are uniformly distributed on the complex sphere of radius :
 .
. ![\[\Var(\omega^* A\omega) = \frac{n}{n+1} \left( \left\|A\right\|_{\rm F}^2 - \frac{1}{n} |\tr A|^2 \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-aacfa2afb45905f6abe0697c769cd1b7_l3.png "Rendered by QuickLaTeX.com")
Optimality Properties
Let us finally address the question of what the best choice of test vectors is for the Girard–Hutchinson estimator. We will state two results with different restrictions on .
Our first result, due to Hutchinson, is valid for real symmetric matrices with real test vectors.
Optimality (independent test vectors with independent coordinates). If the test vectors  are isotropic (2), independent from each other, and have independent entries, then for any fixed real symmetric matrix , the minimum variance for is obtained when are populated with random signs
are isotropic (2), independent from each other, and have independent entries, then for any fixed real symmetric matrix , the minimum variance for is obtained when are populated with random signs  .
.
The next optimality results will have real and complex versions. To present the results for  -valued and an
-valued and an  -valued test vectors on unified footing, let
-valued test vectors on unified footing, let  denote either or . We let a -Hermitian matrix be either a real symmetric matrix (if
denote either or . We let a -Hermitian matrix be either a real symmetric matrix (if  ) or a complex Hermitian matrix (if
) or a complex Hermitian matrix (if  ). Let a -unitary matrix be either a real orthogonal matrix (if ) or a complex unitary matrix (if ).
). Let a -unitary matrix be either a real orthogonal matrix (if ) or a complex unitary matrix (if ).
The condition that the vectors have independent entries is often too restrictive in practice. It rules out, for instance, the case of uniform vectors on the sphere. If we relax this condition, we get a different optimal distribution:
Optimality (independent test vectors). Consider any set  of -Hermitian matrices which is invariant under -unitary similary transformations:
of -Hermitian matrices which is invariant under -unitary similary transformations:
![\[\text{If $A \in \mathscr{A}$ and $U$ is $\field$-unitary, then $U^*AU \in \mathscr{A}$.}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-18b4216d44b2364ea39ed4a078a067af_l3.png "Rendered by QuickLaTeX.com")
Assume that the test vectors are independent and isotropic (2). The worst-case variance  is minimized by choosing uniformly on the -sphere:
is minimized by choosing uniformly on the -sphere:  .
.
More simply, if you wants your stochastic trace estimator to be effective for a class of inputs (closed under -unitary similarity transformations) rather than a single input matrix , then the best distribution are test vectors drawn uniformly from the sphere. Examples of classes of matrices include:
- Fixed eigenvalues. For fixed real eigenvalues
 , the set of all -Hermitian matrices with these eigenvalues.
, the set of all -Hermitian matrices with these eigenvalues. - Density matrices. The class of all trace-one psd matrices.
- Frobenius norm ball. The class of all -Hermitian matrices of Frobenius norm at most 1.
Derivation of Formulas
In this section, we provide derivations of the variance formulas. I have chosen to focus on derivations which are shorter but use more advanced techniques rather than derivations which are longer but use fewer tricks.
Real Gaussians
First assume is real. Since is real symmetric, has an eigenvalue decomposition  , where
, where  is orthogonal and
is orthogonal and  is a diagonal matrix reporting ‘s eigenvalues. Since the real Gaussian distribution is invariant under orthogonal transformations,
is a diagonal matrix reporting ‘s eigenvalues. Since the real Gaussian distribution is invariant under orthogonal transformations,  has the same distribution as
has the same distribution as  . Therefore,
. Therefore,
![\[\Var(\omega^\top A \omega) = \Var(\omega^\top \Lambda \omega) = \Var \left( \sum_{i=1}^n \lambda_i \omega_i^2 \right) = \sum_{i=1}^n \lambda_i^2 \Var(\omega_i^2) = 2\sum_{i=1}^n \lambda_i^2 = 2\left\|A\right\|_{\rm F}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a7416823720bac922fae7cc685892a49_l3.png "Rendered by QuickLaTeX.com")
Here, we used that the variance of a squared standard normal random variable is two.
For non-real matrix, we can break the matrix into its entrywise real and imaginary parts  . Thus,
. Thus,
![\[\Var(\omega^\top A \omega) = \Var(\omega^\top \mathfrak{R}(A) \omega) + \Var(\omega^\top \mathfrak{I}(A) \omega) = 2\left\|\mathfrak{R}(A)\right\|_{\rm F}^2 + 2\left\|\mathfrak{I}(A)\right\|_{\rm F}^2 = 2\left\|A\right\|_{\rm F}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-527980eb3510f2c015106e6945126d41_l3.png "Rendered by QuickLaTeX.com")
Uniform Signs
First, compute
![\[\omega^\top A \omega - \mathbb{E}[\omega^\top A \omega] = \sum_{i,j=1}^n A_{ij} \omega_i\omega_j - \sum_{i=1}^n A_{ii} = \sum_{i\ne j} A_{ij} \omega_i\omega_j + \sum_{i=1}^n A_{ii}(\omega_i^2-1).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4489cc9cb97ee7a0896bc61193d79910_l3.png "Rendered by QuickLaTeX.com")
For a vector of uniform random signs, we have  for every , so the second sum vanishes. Note that we have assumed symmetric, so the sum over
for every , so the second sum vanishes. Note that we have assumed symmetric, so the sum over  can be replaced by two times the sum over
can be replaced by two times the sum over  :
:
![\[\omega^\top A \omega - \mathbb{E}[\omega^\top A \omega] = 2\sum_{i< j} A_{ij} \omega_i\omega_j.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-afc5f6bb40cd00b7897f25d73751f4ca_l3.png "Rendered by QuickLaTeX.com")
Note that  are pairwise independent. As a simple exercise, one can verify that the identity
are pairwise independent. As a simple exercise, one can verify that the identity
![\[\Var(a_1 X_1+\cdots+a_kX_k) = |a_1|^2 \Var(X_1) + \cdots + |a_k|^2 \Var(X_k)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b6fd81d15f564f514f79ab4c33d133d8_l3.png "Rendered by QuickLaTeX.com")
holds for any pairwise independent family of random variances  and numbers
and numbers  . Ergo,
. Ergo,
![\begin{align*}\Var(\omega^\top A\omega) &= \Var(\omega^\top A \omega - \mathbb{E}[\omega^\top A \omega]) \\&= \Var\left(\sum_{i< j} 2A_{ij} \omega_i\omega_j\right) \\&= \sum_{i<j} 4 |A_{ij}|^2 \Var(\omega_i\omega_j) \\&= \sum_{i<j} 4 |A_{ij}|^2 \\&= 2 \sum_{i\ne j} |A_{ij}|^2.\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bbb33f378fabd391c28d938420d3a32b_l3.png "Rendered by QuickLaTeX.com")
In the second-to-last line, we use the fact that  is a uniform random sign, which has variance
is a uniform random sign, which has variance  . The final line is a consequence of the symmetry of .
. The final line is a consequence of the symmetry of .
Uniform on the Real Sphere
The simplest proof is I know is by the “camel principle”. Here’s the story (a lightly edited quotation from MathOverflow):
A father left 17 camels to his three sons and, according to the will, the eldest son was to be given a half of the camels, the middle son one-third, and the youngest son the one-ninth. The sons did not know what to do since 17 is not evenly divisible into either two, three, or nine parts, but a wise man helped the sons: he added his own camel, the oldest son took  camels, the second son took
camels, the second son took  camels, the third son
camels, the third son  camels and the wise man took his own camel and went away.
camels and the wise man took his own camel and went away.
We are interested in a vector which is uniform on the sphere of radius . Performing averages on the sphere is hard, so we add a camel to the problem by “upgrading” to a spherically symmetric vector  which has a random length. We want to pick a distribution for which the computation
which has a random length. We want to pick a distribution for which the computation  is easy. Fortunately, we already know such a distribution, the Gaussian distribution, for which we already calculated
is easy. Fortunately, we already know such a distribution, the Gaussian distribution, for which we already calculated  .
.
The Gaussian vector and the uniform vector on the sphere are related by
![\[g = \sqrt{\frac{a}{n}} \omega,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a93345cf94749f98e715e42bc796501c_l3.png "Rendered by QuickLaTeX.com")
where  is the squared length of the Gaussian vector . In particular, has the distribution of the sum of
is the squared length of the Gaussian vector . In particular, has the distribution of the sum of  squared Gaussian random variables, which is known as a
squared Gaussian random variables, which is known as a  random variable with degrees of freedom.
random variable with degrees of freedom.
Now, we take the camel back. Compute the variance of  using the chain rule for variance:
using the chain rule for variance:
![\[\Var(g^\top A g) = \mathbb{E}[\Var(g^\top A g \mid a)] + \Var(\mathbb{E}[g^\top A g \mid a]).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e4e5ed235fbf5b2e026bcc58bd23becc_l3.png "Rendered by QuickLaTeX.com")
Here,  and
and ![\mathbb{E}[ \cdot \mid a]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6035d77442675ac2f790cfb5417e1072_l3.png "Rendered by QuickLaTeX.com") denote the conditional variance and conditional expectation with respect to the random variable . The quick and dirty ways of working with these are to treat the random variable “like a constant” with respect to the conditional variance and expectation.
denote the conditional variance and conditional expectation with respect to the random variable . The quick and dirty ways of working with these are to treat the random variable “like a constant” with respect to the conditional variance and expectation.
Plugging in the formula  and treating “like a constant”, we obtain
and treating “like a constant”, we obtain
![\begin{align*}\Var(g^\top A g) &= \mathbb{E}[\Var(a/n \cdot \omega^\top A \omega \mid a)] + \Var(\mathbb{E}[a/n \cdot \omega^\top A \omega \mid a]) \\&=\mathbb{E}[(a/n)^2\Var(\omega^\top A \omega)] + \Var(a/n \cdot \mathbb{E}[\omega^\top A \omega]) \\&= \frac{1}{n^2} \mathbb{E}[a^2] \cdot \Var(\omega^\top A \omega) + \frac{1}{n^2} \Var(a) |\mathbb{E} [\omega^\top A \omega]|^2.\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-be052caddf1d08941925fa0283784635_l3.png "Rendered by QuickLaTeX.com")
As we mentioned, is a random variable with degrees of freedom and ![\mathbb{E}[a^2]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-53042ba72cdd3991b14b5d4508da6564_l3.png "Rendered by QuickLaTeX.com") and
and  are known quantities that can be looked up:
are known quantities that can be looked up:
![\[\mathbb{E}[a^2] = n(n+2), \quad \Var(a) = 2n.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-59ecda0ea21d92e43e3182d5cc5a7217_l3.png "Rendered by QuickLaTeX.com")
We know and ![\mathbb{E} [\omega^\top A \omega] = \tr A](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-293908b9583df45d93349435d76b981a_l3.png "Rendered by QuickLaTeX.com") . Plugging these all in, we get
. Plugging these all in, we get
![\[2\left\|A\right\|_{\rm F}^2 = \frac{n+2}{n} \Var(\omega^\top A\omega) + \frac{2}{n} |\tr A|^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1c9b70fd4e5bc6ca4006114830d45619_l3.png "Rendered by QuickLaTeX.com")
Rearranging, we obtain
![\[\Var(\omega^\top A\omega) = \frac{2n}{n+2} \left( \left\|A\right\|_{\rm F}^2 - \frac{1}{n}|\tr A|^2\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7ab53e5895f9a1f474f5bf99fbec5662_l3.png "Rendered by QuickLaTeX.com")
Complex Gaussians
The trick is the same as for real Gaussians. By invariance of complex Gaussian random vectors under unitary transformations, we can reduce to the case where is a diagonal matrix populated with eigenvalues . Then
![\[\Var(\omega^*A \omega) = \Var \left( \sum_{i=1}^n \lambda_i |\omega_i|^2 \right) = \sum_{i=1}^n \Var(|\omega_i|^2) \lambda_i^2 = \sum_{i=1}^n \lambda_i^2 = \left\|A\right\|_{\rm F}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-68f4685a4cd845b98fc1a8fd1494e00a_l3.png "Rendered by QuickLaTeX.com")
Here, we use the fact that  is a random variable with two degrees of freedom, which has variance four.
is a random variable with two degrees of freedom, which has variance four.
Random Phases
The trick is the same as for uniform signs. A short calculation (remembering that is Hermitian and thus  ) reveals that
) reveals that
![\[\Var\left( \omega^* A \omega \right) = \Var \left( \sum_{i<j} 2 \Re(A_{ij} \overline{\omega_i} \omega_j) \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b0e61723c22b056d1aca51694c407e6d_l3.png "Rendered by QuickLaTeX.com")
The random variables  are pairwise independent so we have
are pairwise independent so we have
![\[\Var\left( \omega^* A \omega \right) = \Var \left( \sum_{i<j} 2 \Re(A_{ij} \overline{\omega_i} \omega_j) \right) = 4\sum_{i<j} \Var \left( \Re(A_{ij} \overline{\omega_i} \omega_j) \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f2d77eb554a1e1ffbe4370efd8c704fb_l3.png "Rendered by QuickLaTeX.com")
Since  is uniformly distributed on the complex unit circle, we can assume without loss of generality that
is uniformly distributed on the complex unit circle, we can assume without loss of generality that  . Thus, letting
. Thus, letting  be uniform on the complex unit circle,
be uniform on the complex unit circle,
![\[\Var\left( \omega^* A \omega \right) = 4\sum_{i<j} \Var \left( |A_{ij}|\Re(\phi)) \right) = 4\Var\left( \Re(\phi) \right)\sum_{i<j}|A_{ij}|^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-76d2ce84714c4549a86686259bd96847_l3.png "Rendered by QuickLaTeX.com")
The real and imaginary parts of have the same distribution so
![\[1 = \Var(\phi) = \Var(\Re \phi) + \Var(\Im \phi) = 2 \Var(\Re \phi)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f83462ae4de80311482849de445edd5a_l3.png "Rendered by QuickLaTeX.com")
so  . Thus
. Thus
![\[\Var\left( \omega^* A \omega \right) = 2 \sum_{i<j}|A_{ij}|^2 = \sum_{i\ne j} |A_{ij}|^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-436eeb79ad0eddde0752f1a398397ad5_l3.png "Rendered by QuickLaTeX.com")
Uniform on the Complex Sphere: Derivation 1 by Reduction to Real Case
There are at least three simple ways of deriving this result: the camel trick, reduction to the real case, and Haar integration. Each of these techniques illustrates a trick that is useful in its own right beyond the context of trace estimation. Since we have already seen an example of the camel trick for the real sphere, I will present the other two derivations.
Let us begin with the reduction to the real case. Let  and
and  denote the real and imaginary parts of a vector or matrix, taken entrywise. The key insight is that if is a uniform random vector on the complex sphere of radius , then
denote the real and imaginary parts of a vector or matrix, taken entrywise. The key insight is that if is a uniform random vector on the complex sphere of radius , then
![\[\mathscr{R}(\omega) := \twobyone{\mathfrak{R}(\omega)}{\mathfrak{I}(\omega)}\in\real^{2n} \quad \text{is a uniform random vector on the real sphere of radius $\sqrt{n}$}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0ff873eff96e863cf02d36e65a5ca1be_l3.png "Rendered by QuickLaTeX.com")
We’ve converted the complex vector into a real vector  .
.
Now, we need to convert the complex matrix into a real matrix  . To do this, recall that one way of representing complex numbers is by
. To do this, recall that one way of representing complex numbers is by  matrices:
matrices:
![\[a + bi \iff \twobytwo{a}{-b}{b}{a}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-21b802836b33431568e5d854455d87d1_l3.png "Rendered by QuickLaTeX.com")
Using this correspondence addition and multiplication of complex numbers can be carried by addition and multiplication of the corresponding matrices.
To convert complex matrices to real matrices, we use a matrix-version of the same representation:
![\[\mathscr{R}(A) = \twobytwo{\mathfrak{R}(A)}{-\mathfrak{I}(A)}{\mathfrak{I}(A)}{\mathfrak{R}(A)}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-12a37c4298c9e2d49dfa2f3ac32fe573_l3.png "Rendered by QuickLaTeX.com")
One can check that addition and multiplication of complex matrices can be carried out by addition and multiplication of the corresponding “realified” matrices, i.e.,
![\[\mathscr{R}(A + B) = \mathscr{R}(A) + \mathscr{R}(B), \quad \mathscr{R}(A\cdot B) = \mathscr{R}(A) \cdot \mathscr{R}(B)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4e7fe7da4edb58f1ee1bb8a2b1d2a78b_l3.png "Rendered by QuickLaTeX.com")
holds for all complex matrices and .
We’ve now converted complex matrix and vector into real matrix and vector . Let’s compare to  . A short calculation reveals
. A short calculation reveals
![\[\omega^*A\omega = \mathscr{R}(\omega)^\top \mathscr{R}(A)\mathscr{R}(\omega) .\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d92927d567b8907621af83ab283672a5_l3.png "Rendered by QuickLaTeX.com")
Since is a uniform random vector on the sphere of radius ,  is a uniform random vector on the sphere of radius
is a uniform random vector on the sphere of radius  . Thus, by the variance formula for the real sphere, we get
. Thus, by the variance formula for the real sphere, we get
![\[\Var(\omega^*A\omega) = \Var[(\sqrt{2}\mathscr{R}(\omega))^\top (\mathscr{R}(A)/2)(\sqrt{2}\mathscr{R}(\omega) )] = \frac{4n}{2n+2} \left[ \|\mathscr{R}(A)/2\|_{\rm F}^2 - \frac{1}{8n}(\tr\mathscr{R}(A))^2 \right].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ff16ba8dd015218ea642633d77f2a37a_l3.png "Rendered by QuickLaTeX.com")
A short calculation verifies that  and
and  . Plugging this in, we obtain
. Plugging this in, we obtain
![\[\Var(\omega^*A\omega)= \frac{n}{n+1} \left[ \|A\|_{\rm F}^2 - \frac{1}{n}(\tr A)^2 \right].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c9186eb813af3cd67173d73e32885a22_l3.png "Rendered by QuickLaTeX.com")
Uniform on the Complex Sphere: Derivation 2 by Haar Integration
The proof by reduction to the real case requires some cumbersome calculations and requires that we have already computed the variance in the real case by some other means. The method of Haar integration is more slick, but it requires some pretty high-power machinery. Haar integration may be a little bit overkill for this problem, but this technique is worth learning as it can handle some truly nasty expected value computations that appear, for example, in quantum information.
We seek to compute
![\[\mathbb{E} [(\omega^*A \omega)^2].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8e3e10402f389b06dcd42db97c5ed116_l3.png "Rendered by QuickLaTeX.com")
The first trick will be to write this expession using a single matrix trace using the tensor (Kronecker) product  . For those unfamiliar with the tensor product, the main properties we will be using are
. For those unfamiliar with the tensor product, the main properties we will be using are
(6) ![\[(A\otimes B) (C\otimes D) = (AB) \otimes (CD), \quad \tr(A\otimes B) = \tr A \cdot \tr B. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c5ea1a0235766ad15b67d02b47cfea2e_l3.png "Rendered by QuickLaTeX.com")
We saw in the proof of unbiasedness that
![\[\omega^* A \omega = \tr (\omega^*A\omega) = \tr (A \omega\omega^*).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-578bb521ecfb65fc4025f13431673b08_l3.png "Rendered by QuickLaTeX.com")
Therefore, by (6),
![\[(\omega^*A\omega)^2 = (\tr [A \omega\omega^*])^2 = \tr [A\omega\omega^* \otimes A\omega\omega^*] = \tr [(A\otimes A) (\omega\omega^* \otimes \omega\omega^*)].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5161bc0d787be08130c4cfaed0c84489_l3.png "Rendered by QuickLaTeX.com")
Thus, to evaluate ![\mathbb{E}[(\omega^*A\omega)^2]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-98fe9a5e8220c22709c9d6ade6c3141b_l3.png "Rendered by QuickLaTeX.com") , it will be sufficient to evaluate
, it will be sufficient to evaluate ![\mathbb{E}[\omega\omega^* \otimes \omega\omega^*]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-06ac3d64041068176a86563cec4c67ba_l3.png "Rendered by QuickLaTeX.com") . Forunately, there is a useful formula for these expectation provided by a field of mathematics known as representation theory (see Lemma 1 in this paper):
. Forunately, there is a useful formula for these expectation provided by a field of mathematics known as representation theory (see Lemma 1 in this paper):
![\[\mathbb{E}[ \omega\omega^* \otimes \omega\omega^*] = \frac{2n}{n+1} \operatorname{Proj}_{\operatorname{Sym}^2(\complex^n)}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e5eddca3275c6bbb82fa6b789efe7664_l3.png "Rendered by QuickLaTeX.com")
Here,  is the orthogonal projection onto the space of symmetric two-tensors
is the orthogonal projection onto the space of symmetric two-tensors  . Therefore, we have that
. Therefore, we have that
![\[\mathbb{E}[(\omega^*A\omega)^2] = \tr [(A\otimes A) \mathbb{E}(\omega\omega^* \otimes \omega\omega^*)] = \frac{2n}{n+1} \tr [(A\otimes A) \operatorname{Proj}_{\operatorname{Sym}^2(\complex^n)}].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6c4f09e537808effd6c51c0aa4d20f6e_l3.png "Rendered by QuickLaTeX.com")
To evalute the trace on the right-hand side of this equation, there is another formula (see Lemma 6 in this paper):
![\[\tr \left[(A\otimes B) \operatorname{Proj}_{\operatorname{Sym}^2(\complex^n)}\right] = \frac{1}{2} \left( \tr(AB) + \tr A \cdot \tr B \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3ea7660d7e72964cf11ef2239731a497_l3.png "Rendered by QuickLaTeX.com")
Therefore, we conclude
![\begin{align*}\Var(\omega^* A \omega) &= \mathbb{E}[(\omega^*A\omega)^2] - (\mathbb{E}[\omega^*A\omega])^2 \\&= \frac{2n}{n+1}\tr [(A\otimes A) \operatorname{Proj}_{\operatorname{Sym}^2(\complex^n)}] - (\tr A)^2 \\&= \frac{n}{n+1}\left[ \tr A^2 + (\tr A)^2 \right] - (\tr A)^2 \\&= \frac{n}{n+1}\left[ \left\|A\right\|_{\rm F}^2 - \frac{1}{n} (\tr A)^2 \right].\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7af313e9e07f20b93b0de83867f20a04_l3.png "Rendered by QuickLaTeX.com")
Proof of Optimality Properties
In this section, we provide proofs of the two optimality properties.
Optimality: Independent Vectors with Independent Coordinates
Assume is real and symmetric and suppose that is isotropic (2) with independent coordinates. The isotropy condition
![\[\mathbb{E}[\omega\omega^\top] = I\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-232c1e956304b14a7a6f4b55f9ba35e3_l3.png "Rendered by QuickLaTeX.com")
implies that ![\mathbb{E}[\omega_i\omega_j] = \delta_{ij}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9986528214c0653217367aca2a90d568_l3.png "Rendered by QuickLaTeX.com") , where
, where  is the Kronecker symbol. Using this fact, we compute the second moment:
is the Kronecker symbol. Using this fact, we compute the second moment:
![\begin{align*}\mathbb{E}[ (\omega^*A \omega)^2] &= \mathbb{E}\left[ \left( \sum_{i=1}^n A_{ii} \omega_i^2 +2 \sum_{i<j} A_{ij}\omega_i\omega_j) \right)^2\right] \\&= \sum_{i=1}^n A_{ii}^2 \mathbb{E}[\omega_i^4] + \sum_{i<j} (2A_{ii}A_{jj}+4A_{ij}^2) \mathbb{E}[\omega_i^2]\mathbb{E}[\omega_j^2] \\&= \sum_{i=1}^n A_{ii}^2 \mathbb{E}[\omega_i^4] + \sum_{i<j} (2A_{ii}A_{jj}+4A_{ij}^2) .\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4115914a6e648438e66028437f38ef2a_l3.png "Rendered by QuickLaTeX.com")
Thus
![\[\Var(\omega^*A\omega) = \mathbb{E}[ (\omega^*A \omega)^2] - (\mathbb{E}[\omega^* A \omega])^2 = \sum_{i=1}^n A_{ii}^2 (\mathbb{E}[|\omega_i|^4]-1) + 4\sum_{i<j} A_{ij}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-006e2eb8d5f2162654d8c2de39f5a8bc_l3.png "Rendered by QuickLaTeX.com")
The variance is minimized by choosing with  as small as possible. Since
as small as possible. Since  , the smallest possible value for is
, the smallest possible value for is  , which is obtained by populating with random signs.
, which is obtained by populating with random signs.
Optimality: Independent Vectors
This result appears to have first been proven by Richard Kueng in unpublished work. We use an argument suggested to me by Robert J. Webber.
Assume is a class of -Hermitian matrices closed under -unitary similarity transformations and that is an isotropic random vector (2). Decompose the test vector as
![\[\omega = a \cdot s \quad \text{for} \quad a \in [0,+\infty), \: s \in\{x\in \field^n : x^*x = n \}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-11867b7bff40d97d79a74d5136774fd9_l3.png "Rendered by QuickLaTeX.com")
First, we shall show that the variance is reduced by replacing  with a vector
with a vector  drawn uniformly from the sphere
drawn uniformly from the sphere
(7) ![\[\sup_{A\in\mathscr{A}} \Var(\tilde{\omega}^*A\tilde{\omega}) \le \sup_{A\in\mathscr{A}} \Var(\omega^*A\omega \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e54c170954072838232ab5ff7c78cf25_l3.png "Rendered by QuickLaTeX.com")
where
(8) ![\[\tilde{\omega} = a\cdot t \quad \text{and}\quad t\sim \text{Uniform} \{ x \in \field^n :x^*x = n \} \quad \text{is independent of $a$}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-cb668b2c9f168bca81deb51a17726b1d_l3.png "Rendered by QuickLaTeX.com")
Note that such a can be generated as  for a uniformly random -unitary matrix . Therefore, we have
for a uniformly random -unitary matrix . Therefore, we have
![\begin{align*}\sup_{A\in\mathscr{A}} \Var(\tilde{\omega}^*A\tilde{\omega})&= \sup_{A\in\mathscr{A}} \left[\mathbb{E}[(\tilde{\omega}^*A\tilde{\omega})^2] - (\tr A)^2\right]\\&= \sup_{A\in\mathscr{A}} \left[\mathbb{E}[a^2 \cdot s^*(Q^*AQ)s] - (\tr (Q^*AQ))^2\right].\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-83564c7ba654655b42890c8adb65636f_l3.png "Rendered by QuickLaTeX.com")
Now apply Jensen’s inequality only over the randomness in to obtain
![\begin{align*}\sup_{A\in\mathscr{A}} \Var(\tilde{\omega}^*A\tilde{\omega})&= \sup_{A\in\mathscr{A}} \left[\mathbb{E}[a^2 \cdot s^*(Q^*AQ)s] - (\tr (Q^*AQ))^2\right] \\&\le \mathbb{E}_Q \sup_{A\in\mathscr{A}} \left[\mathbb{E}_{a,s}[a^2 \cdot s^*(Q^*AQ)s] - (\tr (Q^*AQ))^2\right].\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f182f68bcb3cbe40c8b44cf5b585e474_l3.png "Rendered by QuickLaTeX.com")
Finally, note that since is closed under -unitary similarity transformations, the supremum over  for
for  is the same as the supremum of , so we obtain
is the same as the supremum of , so we obtain
![\begin{align*}\sup_{A\in\mathscr{A}} \Var(\tilde{\omega}^*A\tilde{\omega})&\le \mathbb{E}_Q \sup_{A\in\mathscr{A}} \left[\mathbb{E}_{a,s}[a^2 \cdot s^*(Q^*AQ)s] - (\tr (Q^*AQ))^2\right] \\&= \mathbb{E}_Q \sup_{A\in\mathscr{A}} \left[\mathbb{E}_{a,s}[a^2 \cdot s^*As] - (\tr A)^2\right] \\&= \sup_{A\in\mathscr{A}} \Var(\omega^*A\omega).\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bd5736cb133d33ed28ab0f2305ac9678_l3.png "Rendered by QuickLaTeX.com")
We have successfully proven (7). This argument is a specialized version of a far more general result which appears as Proposition 4.1 in this paper.
Next, we shall prove
(9) ![\[\sup_{A\in\mathscr{A}} \Var(t^*At) \le \sup_{A\in\mathscr{A}} \Var(\tilde{\omega}^*A\tilde{\omega}), \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0de32ccbfe09388b9d36757b7f140a8e_l3.png "Rendered by QuickLaTeX.com")
where is still defined as in (8). Indeed, using the chain rule for variance, we obtain
![\begin{align*}\Var(\tilde{\omega}^*A\tilde{\omega})&= \Var(a^2\cdot t^*At) \\&= \mathbb{E}[\Var(a^2\cdot t^* A t \mid a)] + \Var(\mathbb{E}[a^2\cdot t^* A t \mid a]) \\&= \mathbb{E}[a^4]\Var(t^* A t )+ (\tr A)^2\Var(a^2) \\&\ge \mathbb{E}[a^4]\Var(t^* A t ).\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c74465c627f5e70f943ce415fbfafd22_l3.png "Rendered by QuickLaTeX.com")
Here, we have used that is uniform on the sphere and thus ![\mathbb{E}[t^*At] = \tr A](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6ee9ad07ec8316cc6003116e3c311189_l3.png "Rendered by QuickLaTeX.com") . By definition, is the length of divided by . Therefore,
. By definition, is the length of divided by . Therefore,
![\[\mathbb{E}[a^2] = \frac{1}{n}\mathbb{E}[\omega^*\omega] = \frac{1}{n} \mathbb{E}[\tr (\omega\omega^*)] = \frac{1}{n} \tr (\mathbb{E}[\omega\omega^*]) = \frac{\tr I}{n} = 1.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4da8a9a33ffb6559da8625435549f7c2_l3.png "Rendered by QuickLaTeX.com")
Therefore, by Jensen’s inequality,
![\[\mathbb{E}[a^4] = \mathbb{E}[(a^2)^2] \ge (\mathbb{E}[a^2])^2 = 1.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-356fd56d5d04dbda45fa992ae083be0f_l3.png "Rendered by QuickLaTeX.com")
Thus
![\[\Var(\tilde{\omega}^*A\tilde{\omega}) \ge \mathbb{E}[a^4]\Var(t^* A t ) \ge \Var(t^*At) \quad \text{for every }A,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fc9331e3508e9102014ecc83f4517cc5_l3.png "Rendered by QuickLaTeX.com")
which proves (9).
 be random vectors and let
be random vectors and let  denote their tensor product. Assume the vectors
denote their tensor product. Assume the vectors  are isotropic, in the sense that
are isotropic, in the sense that ![\[\expect[x_i^{\vphantom{\top}} x_i^\top] = I.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5e65b0d7cf66e1cecc4c60470eca40af_l3.png "Rendered by QuickLaTeX.com")
 inherits the isotropy property as well
inherits the isotropy property as well ![\expect[xx^\top] = I](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-693de07bc613a6824b8000f4615ccf85_l3.png "Rendered by QuickLaTeX.com") . As a consequence, we can use the vector
. As a consequence, we can use the vector ![\expect[x^\top Ax] = \tr(A)](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-99c590c818d205b76d1b6ab2b4391edb_l3.png "Rendered by QuickLaTeX.com") . Trace estimation has been a frequent topic on this blog.
. Trace estimation has been a frequent topic on this blog.
 ? This question was addressed by Raphael Meyer and Haim Avron. The variance of the trace estimator
? This question was addressed by Raphael Meyer and Haim Avron. The variance of the trace estimator  is
is ![\[\Var(x^\top A x) = \expect[(x^\top A x)^2] - \expect[x^\top A x]^2 = \expect[(x^\top A x)^2] - \tr(A)^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5647f8054d7455519ae8e1bef31af139_l3.png "Rendered by QuickLaTeX.com")
![\expect[(x^\top A x)^2]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b5fbf8e67e4ff29170a0eebe078ce961_l3.png "Rendered by QuickLaTeX.com") . Suppose that the individual base vectors
. Suppose that the individual base vectors ![\[\expect[(x_i^\top A x_i)^2] \le \alpha \tr(A)^2 \quad \text{for every psd matrix } A.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-277e90ec9bcf7846732486a3c5953375_l3.png "Rendered by QuickLaTeX.com")
 . Under assumption (1), Meyer and Avron show that the tensor-product trace estimator
. Under assumption (1), Meyer and Avron show that the tensor-product trace estimator ![\[\expect[(x^\top A x)^2] \le \alpha^\ell \tr(A)^2 \quad \text{for any psd matrix } A.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ee2f7f4328d1d2f7117f850c28a62528_l3.png "Rendered by QuickLaTeX.com")
 for any vector
for any vector  . Observe, the constant in the bound (2) is exponentially larger than the constant in bound (1). Unfortunately, as Meyer and Avron show, this exponentially large variance is a real property of the tensor-structured trace estimator, at least on worst-case examples.
. Observe, the constant in the bound (2) is exponentially larger than the constant in bound (1). Unfortunately, as Meyer and Avron show, this exponentially large variance is a real property of the tensor-structured trace estimator, at least on worst-case examples.
 is a tensor product of isotropic vectors
is a tensor product of isotropic vectors  and
and  , and suppose that
, and suppose that ![\[\expect[(y^\top A_1 y)^2] \le \alpha_1 \tr(A_1)^2 \quad \text{and} \quad \expect[(z^\top A_2 z)^2] \le \alpha_2 \tr(A_2)^2 \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9b8a7bf17b8f16b0ec73e0027423055e_l3.png "Rendered by QuickLaTeX.com")
 and
and  . Now, let
. Now, let  psd matrix, and partition
psd matrix, and partition ![\[A = \begin{bmatrix} A_{11} & \cdots & A_{1d_1} \\ \vdots & \ddots & \vdots \\ A_{d_1 1} & \cdots & A_{d_1 d_1} \end{bmatrix}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-43bb38960318d2dc04d04e021243f074_l3.png "Rendered by QuickLaTeX.com")

 alone and applying (3), we obtain
alone and applying (3), we obtain ![\begin{align*}\expect_y [(x^\top A x)^2] &\le \alpha_1 \left( \tr \begin{bmatrix} z^\top A_{11}z & \cdots & z^\top A_{1d_1}z \\ \vdots & \ddots & \vdots \\ z^\top A_{d_1 1}z & \cdots & z^\top A_{d_1 d_1}z \end{bmatrix} \right)^2 \\ &= \alpha_1 [z^\top(A_{11}+\cdots+ A_{d_1d_1})z]^2.\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4536f123e88a9b329362cc19825464cc_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*}\expect [(x^\top A x)^2] &\le \alpha_1 \alpha_2 \tr(A_{11}+\cdots+ A_{d_1d_1})^2=\alpha_1 \alpha_2\tr(A)^2.\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5f49a9eb10fd37e189a8f518add54828_l3.png "Rendered by QuickLaTeX.com")
 . Voilà! We have deduced the bound
. Voilà! We have deduced the bound ![\[\expect [(x^\top A x)^2] \le \alpha_1\alpha_2 \tr(A)^2,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-434b9be6486b07cf1509bbe664e7f3d4_l3.png "Rendered by QuickLaTeX.com")
 be random vectors in
be random vectors in  drawn uniformly at random from the sphere of radius
drawn uniformly at random from the sphere of radius  is the ratio of the (hyper-)surface area of
is the ratio of the (hyper-)surface area of  -dimensional
-dimensional ![\[q \coloneqq x^\top Ax\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2335446c01894126b9be9427e85de438_l3.png "Rendered by QuickLaTeX.com")
![\[\hat{\tr}\coloneqq \frac{1}{m}\sum_{i=1}^m x_i^\top Ax_i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f3db7ad20e68a6a0d6089c98794613f1_l3.png "Rendered by QuickLaTeX.com")
 and
and ![\expect[q] = \expect[\hat{\tr}] = \tr A](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-41d88b5cbaa2e924f0d83e85fd3d76e8_l3.png "Rendered by QuickLaTeX.com") . The goal of this post will be to bound the probability of these quantities being much smaller or larger than the trace of
. The goal of this post will be to bound the probability of these quantities being much smaller or larger than the trace of  independent copies of the random variable
independent copies of the random variable ![\[\overline{A} = A - \frac{\tr A}{n}I.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bd4e8dbd667c23444824ae5ce6aa8db4_l3.png "Rendered by QuickLaTeX.com")
 has the effect of shifting
has the effect of shifting  has trace zero.
has trace zero.
![\[q = x^\top A x = x^\top \overline{A} x + \frac{\tr A}{n} \cdot x^\top I x = x^\top \overline{A} x + \tr A.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3bcc2b942b5442a19b03b3b012fbfedb_l3.png "Rendered by QuickLaTeX.com")
 . Rearranging, we see that the error
. Rearranging, we see that the error  satisfies
satisfies![\[\overline{q} = q-\tr A = x^\top \overline{A}x.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d2c3289e2fa1a4a5a59762b69593fcb1_l3.png "Rendered by QuickLaTeX.com")
 depends only on the centered matrix
depends only on the centered matrix  , and the
, and the  . These observations will be important later.
. These observations will be important later.![\[\xi_z(\theta) = \log (\expect [\exp(\theta z)]).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-75f376a73cb1e931a07fb50331747dcb_l3.png "Rendered by QuickLaTeX.com")
 , where
, where  is a
is a 
![\expect[a^2] = 1](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5a29d04b84a1f93ace9e404ce3616f54_l3.png "Rendered by QuickLaTeX.com") .
.![\expect[\norm{g}^2] = \sum_{i=1}^n \expect[g_i^2] = n](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-454dd5415485ca62bb66120b18283c66_l3.png "Rendered by QuickLaTeX.com") . But also,
. But also, ![\expect[\norm{g}^2] = \expect[a^2] \cdot \expect[\norm{x}^2] = \expect[a^2] \cdot n](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f153f4a0af6e2dd00a85f40f2ff2fca8_l3.png "Rendered by QuickLaTeX.com") . Therefore,
. Therefore, ![\expect[a^2]=1](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0bd7a7c95fafaa9724e054eb87cba203_l3.png "Rendered by QuickLaTeX.com") .
.![\[g^\top \overline{A} g = a^2 \cdot x^\top \overline{A} x = a^2 \cdot \overline{q}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5e24054c3179f84adac8e8f2c69d1514_l3.png "Rendered by QuickLaTeX.com")
![\[\xi_{\overline{q}}(\theta) \le \xi_{g^\top A g}(\theta) \quad \text{for all } \theta \in \real.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-34b5802e38a63f46468b24fbd0108a08_l3.png "Rendered by QuickLaTeX.com")
 be a random variable with expectation
be a random variable with expectation ![\[\xi_{z}(\theta) \le \xi_{bz}(\theta) \quad \text{for all } \theta \in \real.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-634696ad9a505fc68c577e80323c4324_l3.png "Rendered by QuickLaTeX.com")
 and
and  denote expectations take over the randomness in
denote expectations take over the randomness in ![\expect[\cdot] = \expect_z[\expect_b[\cdot ]]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-332d248f563a792e91ea931b068aa939_l3.png "Rendered by QuickLaTeX.com") . Begin with the right-hand side and invoke
. Begin with the right-hand side and invoke ![\[\xi_{bz}(\theta) = \xi_z(\theta) = \log (\expect_z [\expect_b [\exp(\theta bz)]]) \ge \log (\expect_z [\exp(\theta \expect_b[b]z)]) = \xi_z(\theta).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fa5226c666db21a3f56f6bdfdcbb1170_l3.png "Rendered by QuickLaTeX.com")
![\expect[b] = 1](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bb25ca2a980b2795822bf62c2d392b47_l3.png "Rendered by QuickLaTeX.com") and the definition of the cgf.
and the definition of the cgf.
 for all
for all  .
. for a trace-zero matrix
for a trace-zero matrix ![\[\xi_{\overline{q}}(\theta) \le \xi_{g^\top \overline{A} g}(\theta) \le \frac{\theta^2 \norm{\overline{A}}_{\rm F}^2}{1 - 2\theta \norm{\overline{A}}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-623e28881a1cb46a4526687b07e28e0e_l3.png "Rendered by QuickLaTeX.com")
![\[\prob \{ x^\top A x - \tr(A) \ge t \} \le \exp \left( - \frac{t^2/2}{2 \norm{\overline{A}}_{\rm F}^2 + 2 \overline{\norm{\overline{A}}t}} \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-16071627e38437191476b04f643b1057_l3.png "Rendered by QuickLaTeX.com")
 by instantiating this result with
by instantiating this result with  .
. ![\[\prob \{ |x^\top A x - \tr(A)| \ge t \} \le 2\exp \left( - \frac{t^2/2}{2 \norm{\overline{A}}_{\rm F}^2 + 2 \overline{\norm{\overline{A}}t}} \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f19454359ca5d0e68b0207b865db95db_l3.png "Rendered by QuickLaTeX.com")
 for small
for small  and
and  for large
for large  . This pattern of results “subgaussian scaling for small
. This pattern of results “subgaussian scaling for small ![\[\prob \{ g^\top A g - \tr A \ge t \} \le \exp \left( -\frac{t^2/2}{C\norm{A}_{\rm F}^2 + c t \norm{A}}\right)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-cb3646b736a9e33403f0175d6bc8e296_l3.png "Rendered by QuickLaTeX.com")
 . For vectors on the sphere,
. For vectors on the sphere,  and
and  have been replaced by
have been replaced by  and
and  which are always smaller (and sometimes much smaller). The smaller tail probabilities for
which are always smaller (and sometimes much smaller). The smaller tail probabilities for  . For small
. For small  . The true variance of
. The true variance of  is
is ![\[\Var(q) = \frac{n}{n+2} \cdot 2\norm{\overline{A}}_{\rm F}^2,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-350430c2a39ce9f557afb3d41806c93f_l3.png "Rendered by QuickLaTeX.com")
 easily follow. Indeed, the cgf is additive for independent random variables and satisfies the identity
easily follow. Indeed, the cgf is additive for independent random variables and satisfies the identity  for constant $c, so
for constant $c, so ![\[\xi_{\overline{\tr}}(\theta) = \sum_{i=1}^m \xi_{x_i^\top Ax_i}(\theta/m) \le m \cdot \frac{(\theta/m)^2 \norm{\overline{A}}_{\rm F}^2}{1 - 2(\theta/m)\norm{\overline{A}}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d6d7f289a105bd06e272223f56ee7080_l3.png "Rendered by QuickLaTeX.com")

 of an
of an  matrix
matrix  . The classical method for this purpose is the
. The classical method for this purpose is the ![\[\hat{\tr} = \frac{1}{m} \left( x_1^\top Ax_1 + \cdots + x_m^\top Ax_m \right),\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f27a0c05da428b96172a0a8ab23ca54b_l3.png "Rendered by QuickLaTeX.com")
 are
are ![\[\expect[x_ix_i^\top] = I.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b5ac53011350edc256d9b8c66fdbe7c8_l3.png "Rendered by QuickLaTeX.com")
 .
.![\expect[\hat{\tr}] = \tr(A)](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ad9e9d417b59555f2a6e78e78b6bcbe9_l3.png "Rendered by QuickLaTeX.com") , the
, the  of the Girard–Hutchinson estimator with different choices of test vectors. In that post, I stated the formulas for different choices of test vectors (Gaussian, random signs, sphere) and showed how those formulas could be proven.
of the Girard–Hutchinson estimator with different choices of test vectors. In that post, I stated the formulas for different choices of test vectors (Gaussian, random signs, sphere) and showed how those formulas could be proven.![\[\overline{\lambda} = \frac{\lambda_1 + \cdots + \lambda_n}{n}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3f9e9cf25f6cf20463de5be7e8d40f88_l3.png "Rendered by QuickLaTeX.com")
![\[\Var(\hat{\tr}_{\rm Gaussian}) = \frac{1}{m} \cdot 2 \sum_{i=1}^n \lambda_i^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f8dc441dc68294b0d6ff6af42d3ecef5_l3.png "Rendered by QuickLaTeX.com")
![\[\Var(\hat{\tr}_{\rm sphere}) = \frac{1}{m} \cdot \frac{n}{n+2} \cdot 2\sum_{i=1}^n (\lambda_i - \overline{\lambda})^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6a275f8ba8a47be085e22f679b60b497_l3.png "Rendered by QuickLaTeX.com")
 is smaller than
is smaller than  by a factor of
by a factor of  . This improvement is quite minor. Second, and more importantly,
. This improvement is quite minor. Second, and more importantly,  matrix
matrix  and
and  with a (
with a ( . Below show the variance of Girard–Hutchinson estimator for different distributions for the test vector. We see that the sphere distribution leads to a trace estimate which has a variance 300× smaller than the Gaussian distribution. For this example, the sphere and random sign distributions are similar.
. Below show the variance of Girard–Hutchinson estimator for different distributions for the test vector. We see that the sphere distribution leads to a trace estimate which has a variance 300× smaller than the Gaussian distribution. For this example, the sphere and random sign distributions are similar. )
)

![\[\Var(\hat{\tr}_{\rm signs}) = 2 \sum_{i\ne j} A_{ij}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3a6665f8e55563640aedd5ebb0945409_l3.png "Rendered by QuickLaTeX.com")
 depends on the size of the off-diagonal entries of
depends on the size of the off-diagonal entries of ![\[\tr(A) \coloneqq \sum_{i=1}^n A_{ii}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-80cd9a9ca29d1d3bb13ce28fd80b5e59_l3.png "Rendered by QuickLaTeX.com")
 . Our goal is to form an estimate
. Our goal is to form an estimate ![\[\expect\left[\frac{|\hat{\tr}-\tr(A)|}{\tr(A)}\right] \le \varepsilon \quad \text{using } m= \frac{\rm const}{\varepsilon^2} \text{ matvecs}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-07898a8a2214416cb97b8b72956e3e76_l3.png "Rendered by QuickLaTeX.com")
 ) requires roughly
) requires roughly  matvecs!
matvecs!
![\[\expect\left[\frac{|\hat{\tr}-\tr(A)|}{\tr(A)}\right] \le \varepsilon \quad \text{using } m= \frac{\rm const}{\varepsilon} \text{ matvecs}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b9f186640222c78e5064f83465038b78_l3.png "Rendered by QuickLaTeX.com")
 matvecs to achieve 1% error!
matvecs to achieve 1% error! ![\[\expect\left[\frac{|\hat{\tr}-\tr(A)|}{\tr(A)}\right] \le \varepsilon \quad \text{using } m= \frac{\rm const}{\varepsilon^{0.999}} \text{ matvecs}?\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8bae682300a401dc80869764b302ce8c_l3.png "Rendered by QuickLaTeX.com")
 . The algorithm is allowed to be adaptive: It can use the matvecs
. The algorithm is allowed to be adaptive: It can use the matvecs  it has already collected to decide which vector
it has already collected to decide which vector  to present next. We measure the cost of the algorithm in terms of the number of matvecs alone, and the algorithm knows nothing about the psd matrix
to present next. We measure the cost of the algorithm in terms of the number of matvecs alone, and the algorithm knows nothing about the psd matrix  and
and  . Then
. Then  would be an allowed input vector, but
would be an allowed input vector, but  would not be (too many digits after the decimal place). Similarly,
would not be (too many digits after the decimal place). Similarly,  would not be valid because its entries exceed
would not be valid because its entries exceed  . For this analysis of trace estimation, we use
. For this analysis of trace estimation, we use  (no powers of ten allowed)!
(no powers of ten allowed)!![\[\expect\left[\frac{|\hat{\tr}-\tr(A)|}{\tr(A)}\right] \le \varepsilon \quad \text{using } m= \frac{\rm const}{\varepsilon^{0.999}} \text{ matvecs}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9034edba9bafb68809d24d54f5a830e6_l3.png "Rendered by QuickLaTeX.com")
 of both their inputs.
of both their inputs. with
with  and
and ![\[\text{Case 0: } x^\top y \ge\sqrt{n} \quad \text{or} \quad \text{Case 1: } x^\top y \le -\sqrt{n}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3134941eeedf133f83ba4795b499332f_l3.png "Rendered by QuickLaTeX.com")
 , determines whether they are in case 0 or case 1, and sends Bob a single bit to communicate the answer. This procedure requires
, determines whether they are in case 0 or case 1, and sends Bob a single bit to communicate the answer. This procedure requires  bits of communication.
bits of communication. probability for every pair of inputs
probability for every pair of inputs  bits of communication.
bits of communication. and
and  . For the less familiar, it can be helpful to interpret
. For the less familiar, it can be helpful to interpret  , and consider (but do not form!) the positive semidefinite matrix
, and consider (but do not form!) the positive semidefinite matrix ![\[A = (X+Y)^\top (X+Y).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2b1df104e3d571430963573b54d5c4df_l3.png "Rendered by QuickLaTeX.com")
![\[\tr(A) = \tr(X^\top X) + 2\tr(X^\top Y) + \tr(Y^\top Y) = 2n + 2(x^\top y).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a0f6e916740a9c27733c659418cc15cf_l3.png "Rendered by QuickLaTeX.com")
 :
:![\[\text{Case 0: } \tr(A)\ge 2n + 2\sqrt{n} \quad \text{or} \quad \text{Case 1: } \tr(A) \le 2n-2\sqrt{n}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1fea970636b48c827e4584d3655b9e3c_l3.png "Rendered by QuickLaTeX.com")
 or
or  ) and sends the result to Bob.
) and sends the result to Bob. for some vector
for some vector  whose entries are integers between
whose entries are integers between  and
and  . Since
. Since  , interconverting between
, interconverting between  is trivial. Alice and Bob’s procedure for computing
is trivial. Alice and Bob’s procedure for computing  .
. and sends it to Alice.
and sends it to Alice. and sends it to Bob.
and sends it to Bob. and sends its to Alice.
and sends its to Alice. .
. and
and  are
are  and have
and have  and
and  . We conclude the communication cost for one matvec is
. We conclude the communication cost for one matvec is  bits.
bits. , BestTraceAlgorithm requires at most
, BestTraceAlgorithm requires at most  matvecs and, for any positive semidefinite input matrix
matvecs and, for any positive semidefinite input matrix ![\[\expect\left[\frac{|\hat{\tr}-\tr(A)|}{\tr(A)}\right] \le \varepsilon.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-a9165ea3846d540eb654af9f7f59a5c2_l3.png "Rendered by QuickLaTeX.com")
 matvecs.
matvecs.
![\[\left| \frac{\hat{\tr} - \tr(A)}{\tr(A)} \right| \le \frac{1}{\sqrt{n}},\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8327e1b03c9ba9162fb737e40a192b3a_l3.png "Rendered by QuickLaTeX.com")
 bits. Chakrabati and Regev showed that Gap-Hamming requires
bits. Chakrabati and Regev showed that Gap-Hamming requires  bits of communication (for some
bits of communication (for some  ) to solve the Gap-Hamming problem with
) to solve the Gap-Hamming problem with  , then Alice and Bob fail to solve the Gap-Hamming problem with at least
, then Alice and Bob fail to solve the Gap-Hamming problem with at least  probability. Thus,
probability. Thus, ![\[\text{If } m < \frac{cn}{T} = \Theta\left( \frac{\sqrt{n}}{b+\log n} \right), \quad \text{then } \left| \frac{\hat{\tr} - \tr(A)}{\tr(A)} \right| > \frac{1}{\sqrt{n}} \text{ with probability at least } \frac{1}{3}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-74364fd915239fdaf0889d005378b7ba_l3.png "Rendered by QuickLaTeX.com")
![\[\text{If }\left| \frac{\hat{\tr} - \tr(A)}{\tr(A)} \right| \le \frac{1}{\sqrt{n}}\text{ with probability at least } \frac{2}{3}, \quad \text{then } m \ge \Theta\left( \frac{\sqrt{n}}{b+\log n} \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-81fbd6e8e08c9759a6cbf5ac4f9782e2_l3.png "Rendered by QuickLaTeX.com")
 . Then, by (3) and
. Then, by (3) and ![\[\left| \frac{\hat{\tr} - \tr(A)}{\tr(A)} \right| \le \frac{1}{\sqrt{n}} \quad \text{with probability at least }\frac{2}{3}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-95db791999f5573659f14f5b0d4a386e_l3.png "Rendered by QuickLaTeX.com")
![\[m \ge \Theta\left( \frac{\sqrt{n}}{b+\log n} \right) \text{ matvecs}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8f0975698051029d6273269409146a9f_l3.png "Rendered by QuickLaTeX.com")
 , we conclude that any trace estimation algorithm, even BestTraceAlgorithm, requires
, we conclude that any trace estimation algorithm, even BestTraceAlgorithm, requires![\[m \ge \Theta \left( \frac{1}{\varepsilon (b+\log(1/\varepsilon))} \right) \text{ matvecs}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b3eb651ca114a7fe19f3b8c5d3e64063_l3.png "Rendered by QuickLaTeX.com")
 using even
using even  matvecs. This proves the MMMW theorem.
matvecs. This proves the MMMW theorem.
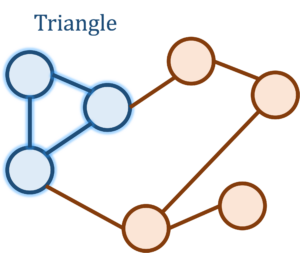
 triplets and checking whether they form a triangle is far too computationally costly for the billions of Facebook accounts. Somehow, we want to do much faster than this, and to achieve this speed we would be willing to settle for an estimate of the triangle count up to some error.
triplets and checking whether they form a triangle is far too computationally costly for the billions of Facebook accounts. Somehow, we want to do much faster than this, and to achieve this speed we would be willing to settle for an estimate of the triangle count up to some error. th entry of
th entry of  are friends and
are friends and  otherwise
otherwise of the matrix
of the matrix  where
where  ,
,  , and
, and  th entry of
th entry of  , which is twice the number of triangles incident on
, which is twice the number of triangles incident on  and
and  are both counted as paths of length 3 for a triangle consisting of
are both counted as paths of length 3 for a triangle consisting of  is counted thrice in the
is counted thrice in the  th, and
th, and  th entries of
th entries of 
 . We assume that we only have access to the matrix
. We assume that we only have access to the matrix  for a vector
for a vector  . Therefore, the matrix
. Therefore, the matrix  , we simply compute matrix–vector products with
, we simply compute matrix–vector products with  .
. probability. Then if one forms the expression
probability. Then if one forms the expression  . Since the entries of
. Since the entries of  are independent, the
are independent, the  is
is  . Consequently, by
. Consequently, by  is
is![\begin{equation*} \mathbb{E} \, x^\top M x = \sum_{i,j=1}^n M_{ij} \mathbb{E} [x_ix_j] = \sum_{i = 1}^n M_{ii} = \operatorname{tr}(M). \end{equation*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-17a6a7cacc94a45f13853dc8f34f1e3a_l3.png "Rendered by QuickLaTeX.com")
 . Thus, the efficiently computable quantity
. Thus, the efficiently computable quantity  equals
equals  and compute the averaged trace estimator
and compute the averaged trace estimator
 remains an unbiased estimator for
remains an unbiased estimator for  , but with reduced variability. Quantitatively, the
, but with reduced variability. Quantitatively, the 
 .” In other words, concentration inequalities can provide quantitative estimates of the likely size of the error when a randomized algorithm is executed.
.” In other words, concentration inequalities can provide quantitative estimates of the likely size of the error when a randomized algorithm is executed.
 . This small example shows both the power and the limitation of Markov’s inequality. On the negative side, our analysis suggests that we might have to wait as much as 100 times the average runtime for the algorithm to complete running with 99% probability; this large huge multiple of 100 seems quite pessimistic. On the other hand, we needed no information whatsoever about how the algorithm works to do this analysis. In general, Markov’s inequality cannot be improved without more assumptions on the random variable
. This small example shows both the power and the limitation of Markov’s inequality. On the negative side, our analysis suggests that we might have to wait as much as 100 times the average runtime for the algorithm to complete running with 99% probability; this large huge multiple of 100 seems quite pessimistic. On the other hand, we needed no information whatsoever about how the algorithm works to do this analysis. In general, Markov’s inequality cannot be improved without more assumptions on the random variable  :
:
 are
are  and variance
and variance  and let
and let  denote the average
denote the average

 . Therefore, by Chebyshev’s inequality,
. Therefore, by Chebyshev’s inequality,
 and are willing to tolerate a failure probability of
and are willing to tolerate a failure probability of 
 . Normal random variables have an exponentially small probability of being more than a few standard deviations above their mean, so it is natural to expect this should be true of
. Normal random variables have an exponentially small probability of being more than a few standard deviations above their mean, so it is natural to expect this should be true of 
 . Hoeffding’s inequality makes the assumption that the summands are bounded, say within an interval
. Hoeffding’s inequality makes the assumption that the summands are bounded, say within an interval ![[a,b]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-336bb22d4b2092329486008f6665b888_l3.png "Rendered by QuickLaTeX.com") .
.
 replaced by the potentially much larger quantity
replaced by the potentially much larger quantity .
. for every
for every  . We continue to denote
. We continue to denote 

 . We conclude that Bernstein’s inequality provides sharper bounds then Hoeffding’s inequality for smaller values of
. We conclude that Bernstein’s inequality provides sharper bounds then Hoeffding’s inequality for smaller values of  , except with failure probability at most
, except with failure probability at most 

![[\mu-B,\mu+B]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bada0c6b976891e43bcc4c3b7508e96e_l3.png "Rendered by QuickLaTeX.com") for every
for every  , then
, then
 samples are needed rather than proportional to
samples are needed rather than proportional to  . The fact that we need proportional to
. The fact that we need proportional to  samples to achieve error
samples to achieve error  to
to  , which is a huge improvement.
, which is a huge improvement. ; for small values of
; for small values of 
 is the
is the  is the
is the 
 . By the
. By the  and
and  where
where  and
and  are the
are the  is the
is the  so
so  and
and  . Since the
. Since the 
 denotes the
denotes the 

 and
and  . Since we often don’t know good bounds for
. Since we often don’t know good bounds for  , one should really use the trace estimator together with an
, one should really use the trace estimator together with an  down from
down from  .
. is an
is an 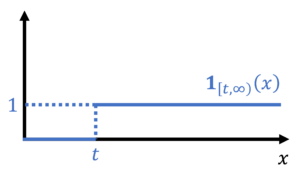
![\begin{equation*} \mathbb{P}\{X \ge t \} = \mathbb{E}[\mathbf{1}_{[t,\infty)}(X)]. \end{equation*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-070609e7e86c3846db2eec810355d5f4_l3.png "Rendered by QuickLaTeX.com")
 by bounding its corresponding indicator function. In particular, we have the inequality
by bounding its corresponding indicator function. In particular, we have the inequality 
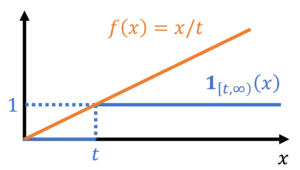
![\begin{equation*} \mathbb{P}\{ X \ge t \} = \mathbb{E}[\mathbf{1}_{[t,\infty)}(X)] \le \mathbb{E} \left[ \frac{X}{t} \right] = \frac{\mathbb{E} X}{t}. \end{equation*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-49a753eda4e591b364f5d4f3e24a0b9b_l3.png "Rendered by QuickLaTeX.com")

 by (11). To obtain sharp and useful bounds on
by (11). To obtain sharp and useful bounds on  we seek bounding functions
we seek bounding functions  in (13) with three properties:
in (13) with three properties: ,
,  should be close to zero,
should be close to zero, ,
,  to be easily computable or boundable.
to be easily computable or boundable. or exponentials
or exponentials  for which we have hopes of computing or bounding
for which we have hopes of computing or bounding  (by increasing
(by increasing  , detracting from our ability to achieve point 2. We shall eventually come up with a best-possible resolution to this dilemma by formulating this as an optimization problem to determine the best choice of the parameter
, detracting from our ability to achieve point 2. We shall eventually come up with a best-possible resolution to this dilemma by formulating this as an optimization problem to determine the best choice of the parameter  to obtain the best possible candidate function of the given form.
to obtain the best possible candidate function of the given form. satisfies the bound (13), and thus by (12),
satisfies the bound (13), and thus by (12),
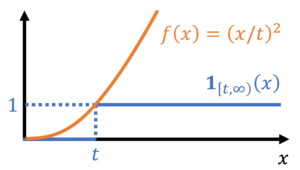
 , is a nonnegative random variable. Thus applying (14) gives
, is a nonnegative random variable. Thus applying (14) gives
 if, and only if,
if, and only if,  . Therefore, by Markov’s inequality,
. Therefore, by Markov’s inequality,
 , where
, where 

 ,
,  , and the
, and the 
 up to the sign of the parameter
up to the sign of the parameter  . Taking logarithms proves the additivity.
. Taking logarithms proves the additivity.
 and consider the cumulant generating function of
and consider the cumulant generating function of  . Then one can show the cumulant generating function bound
. Then one can show the cumulant generating function bound . We have
. We have  . Since the function
. Since the function  is
is  . Taking expectations, we have
. Taking expectations, we have  . One can show by comparing Taylor series that
. One can show by comparing Taylor series that  . Therefore, we have
. Therefore, we have  .
.



 :
:
 , we can apply a small trick. If we apply (20) to the summands
, we can apply a small trick. If we apply (20) to the summands  instead of
instead of 
 . The means of doing often this goes by the fancy name
. The means of doing often this goes by the fancy name 


 .
.