This post is part of a series, Markov Musings, about the mathematical analysis of Markov chains. See here for the first post in the series.
In the previous post, we proved the following convergence results for a reversible Markov chain
![\[\chi^2\left(\rho^{(n)} \, \middle|\middle| \, \pi\right) \le \left( \max \{ \lambda_2, -\lambda_n \} \right)^{2n} \chi^2\left(\rho^{(0)} \, \middle|\middle| \, \pi\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ed65d0043f7a436b0f42a6d096d34e9f_l3.png "Rendered by QuickLaTeX.com")
 denotes the distribution of the chain at time
denotes the distribution of the chain at time  ,
,  denotes the stationary distribution,
denotes the stationary distribution,  denotes the
denotes the  divergence, and
divergence, and  denote the decreasingly ordered eigenvalues of the Markov transition matrix
denote the decreasingly ordered eigenvalues of the Markov transition matrix  . To bound the rate of convergence to stationarity, we therefore must upper bound
. To bound the rate of convergence to stationarity, we therefore must upper bound  and lower bound
and lower bound  .
.
Having to prove separate bounds for two eigenvalues is inconvenient. In the next post, we will develop tools to bound . But what should we do about  Fortunately, there is a trick.
Fortunately, there is a trick.
It Pays to be Lazy
Call a Markov chain lazy if, at every step, the chain has at least a 50% chance of staying put. That is,  for every
for every  .
.
Any Markov chain can be made into a lazy chain. At every step of the chain, flip a coin. If the coin is heads, perform a step of the Markov chain as normal, drawing the next step randomly according to the transition matrix . If the coin comes up tails, do nothing and stay put.
Algebraically, the lazy chain described in the previous paragraph corresponds to replacing the original transition matrix with the lazy transition matrix  , where
, where  denotes the identity matrix. It is easy to see that the stationary distribution for is also a stationary distribution for
denotes the identity matrix. It is easy to see that the stationary distribution for is also a stationary distribution for  :
:
![\[\pi^\top P^{\rm lazy} = \frac{1}{2} \pi^\top P + \frac{1}{2} \pi^\top I = \frac{1}{2} \pi^\top + \frac{1}{2} \pi^\top = \pi^\top.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d33d9a3024c655134a56d89b119cf39c_l3.png "Rendered by QuickLaTeX.com")
![\[\lambda_i^{\rm lazy} = \frac{1+\lambda_i}{2}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ac2938aa6854a708a394222649af1e66_l3.png "Rendered by QuickLaTeX.com")
 are
are  , all of the eigenvalues of the lazy chain are
, all of the eigenvalues of the lazy chain are  . Thus, the smallest eigenvalue of is always and thus, for the lazy chain, the convergence is controlled only by
. Thus, the smallest eigenvalue of is always and thus, for the lazy chain, the convergence is controlled only by  :
: ![\[\chi^2\left(\rho^{(n)} \, \middle|\middle| \, \pi\right) \le \left( \lambda_2^{\rm lazy} \right)^{2n} \chi^2\left(\rho^{(0)} \, \middle|\middle| \, \pi\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-861a132f08a1c2b208d61eb004ed58bb_l3.png "Rendered by QuickLaTeX.com")
Should You be Lazy?
We’ve seen one theoretical argument for why it pays to use lazy Markov chains. But should we use lazy Markov chains in practice? The answer ultimately depends on how we want to use the Markov chain.
Here are two very different ways we could use a Markov chain:
- One-shot sampling. Run the Markov chain once for a fixed number of steps , and use the result as an approximate sample from .
For this use case, it is important that the output is genuinely a sample from , and the possibility of large negative eigenvalues can significantly degrade the convergence. In the extreme case where  is an eigenvalue, the chain will fail to converge to stationarity at all. For this application, the lazy approach may make sense.
is an eigenvalue, the chain will fail to converge to stationarity at all. For this application, the lazy approach may make sense.
- Averaging. Another way we can use a Markov chain is to compute the average of value of a function
 over a random variable
over a random variable  drawn from the stationary distribution:
drawn from the stationary distribution:
To do this, we approximate this expectation by the time average![\[\expect_{x\sim \pi} [f(x)] = \sum_{i=1}^m f(i) \pi_i.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6399c58f0e1b13f3cffac439c145d3b4_l3.png "Rendered by QuickLaTeX.com")
 of the value of
of the value of  over the first
over the first  values
values  of the chain
of the chain![\[\hat{f}_{N}\coloneqq \frac{1}{N}\sum_{n=0}^{N-1} f(x_i).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-591e83a4f5551f6826ddffb5de03ce72_l3.png "Rendered by QuickLaTeX.com")
As we shall see, this averaging process converges at an (asymptotically) slower rate for the lazy chain than the original chain. Therefore, for this application, we should typically just run the chain as-is, and not worry about making it lazy.
The Case Against Laziness
To see why being lazy hurts us for the averaging problem, we will use the Markov chain central limit theorem. As with many random averaging processes, we expect that in the limit of a large number of steps , the Markov chain average
![\[\hat{f}_N = \frac{1}{N}\sum_{n=0}^{N-1} f(x_i)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-615239005583b665db04e6a578abec08_l3.png "Rendered by QuickLaTeX.com")
Informal theorem (Markov chain central limit theorem). Let
denote the states of a Markov chain initialized in the stationary distribution
. For a large number
and variance
where
(1)
![\[\sigma^2 = \Var[f(x_0)] + 2\sum_{n=1}^\infty \Cov(f(x_0),f(x_n)). \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b209aff956ed442df57ac781c0376a2f_l3.png "Rendered by QuickLaTeX.com")
The Markov chain CLT shows that the variance of the Markov chain average depends not only on the variance of in the stationary distribution, but also the covariance between  and later values
and later values  . The faster the covariance decreases, the smaller
. The faster the covariance decreases, the smaller  will be and thus the smaller the error for the Markov chain average.
will be and thus the smaller the error for the Markov chain average.
More formally, the Markov chain CLT is given by the following result:
Theorem (Markov chain central limit theorem). As
,
converges in distribution to a normal random variable with mean zero and variance
![\[\frac{\hat{f}_N - \expect_{x \sim \pi} [f(x)]}{\sqrt{N}}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f5818a8980215e63da79048168aa8b79_l3.png "Rendered by QuickLaTeX.com")
To compare the lazy and non-lazy chains, let’s compute the variance parameter in the Markov chain CLT in terms of the eigenvalues of the chain. For the remainder of this post, let  be any function.
be any function.
Step 1: Spectral Decomposition
Recall that, by the spectral theorem, the transition matrix has eigenvectors  that are orthonormal in the -inner product
that are orthonormal in the -inner product
![\[\langle \varphi_i,\varphi_j \rangle = \expect_{x\sim \pi} [\varphi_i(x)\varphi_j(x)] = \begin{cases}1, & i = j, \\0, & i \ne j.\end{cases}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-139934705e34440f3c903f0e089f580b_l3.png "Rendered by QuickLaTeX.com")
 as defining a function
as defining a function  . Thus, we can expand the function using the eigenvectors
. Thus, we can expand the function using the eigenvectors (2) ![\[f = c_1 \varphi_1 + \cdots + c_m \varphi_m. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c7d7e27ce6d2d6d0e3c721a120eef469_l3.png "Rendered by QuickLaTeX.com")
 is the vector of all ones (or, equivalently, the function that outputs
is the vector of all ones (or, equivalently, the function that outputs  for every output).
for every output).
Step 2: Applying the Transition Matrix to a Function
The transition matrix is defined so that if the Markov chain has probability distribution  at time , then the chain has distribution
at time , then the chain has distribution  at time
at time  . In other words, multiplying by on the right advances a distribution forward one step in time. This leads us to ask, what is the interpretation of multiplying a function by on the left. That is, is there an interpretation to the matrix–vector product
. In other words, multiplying by on the right advances a distribution forward one step in time. This leads us to ask, what is the interpretation of multiplying a function by on the left. That is, is there an interpretation to the matrix–vector product  ?
?
Indeed, there is such an interpretation: The th coordinate of is the expectation of  conditional on the chain starting at
conditional on the chain starting at  :
:
![\[(Pf)(i) = \expect[f(x_1) \mid x_0 = i].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d3abc35eacbcac194f948451539f7778_l3.png "Rendered by QuickLaTeX.com")
(3) ![\[(P^nf)(i) = \expect[f(x_n) \mid x_0 = i]. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3aee313626d01d020c481e25567fe6c1_l3.png "Rendered by QuickLaTeX.com")
 denote a probability distribution which places 100% of the probability mass on the single site . The th entry of
denote a probability distribution which places 100% of the probability mass on the single site . The th entry of  is
is ![\[(P^n f)(i) = \delta_i^\top (P^n f) = (\delta_i^\top P^n) f.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e8c9b07d76e51bf1a6c2e582e9a239a7_l3.png "Rendered by QuickLaTeX.com")
 is the state of the Markov chain after steps when initialized in the initial distribution
is the state of the Markov chain after steps when initialized in the initial distribution  . Thus,
. Thus, ![\[(P^n f)(i) = (\rho^{(n)})^\top f = \sum_{i=1}^m \rho^{(n)}_i f(i) = \expect[f(x_n) \mid x_0=i].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6eaa69991373f0004f94c020fd9d4b3c_l3.png "Rendered by QuickLaTeX.com")
Step 3: Computing the Covariance
With the help of the formula for  and the spectral decomposition of , we are ready to compute the covariances appearing in (1).Let
and the spectral decomposition of , we are ready to compute the covariances appearing in (1).Let  . Then
. Then
(4) ![\[\Cov (f(x_0),f(x_n)) = \expect[f(x_0)f(x_n)] - \expect[f(x_0)]\expect[f(x_n)]. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0d2881b12745eed9e1a985eb8fefa650_l3.png "Rendered by QuickLaTeX.com")
Let’s first compute ![\expect[f(x_0)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c88debcfbbae714aadb6b34e5a6fd646_l3.png "Rendered by QuickLaTeX.com") and
and ![\expect[f(x_n)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-35ed314f41c6654ee1ef7f9631c96e4e_l3.png "Rendered by QuickLaTeX.com") . Since is the vector/function of all ones, we have
. Since is the vector/function of all ones, we have
![\[\expect[f(x_0)] = \expect[f(x_0) \cdot 1] = \expect[f(x_0) \varphi_1(x_0)] = \langle f, \varphi_1\rangle = c_1.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fceebd56048f584bab0bf0ba12254652_l3.png "Rendered by QuickLaTeX.com")
 .
.
Since we assume the chain is initialized in the stationary distribution , it remains in stationarity at time ,  , so we have
, so we have ![\expect[f(x_n)] = \expect[f(x_0)] = c_1](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-703a86f4cdb9f7d354b2f7440826b5e9_l3.png "Rendered by QuickLaTeX.com") .
.
Now, let’s compute ![\expect[f(x_0)f(x_n)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-274aba259d8ec1c94a05588a5b6e3846_l3.png "Rendered by QuickLaTeX.com") . Use the law of total expectation to write
. Use the law of total expectation to write
![\begin{align*}\expect[f(x_0)f(x_n)] &= \sum_{i=1}^m \expect[f(x_0) f(x_n) \mid x_0 = i] \prob\{x_0 = i\} \\&= \sum_{i=1}^m f(i) \expect[f(x_n) \mid x_0 = i] \pi_i.\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2e350d683f2a7cfff71028de3a45dbf8_l3.png "Rendered by QuickLaTeX.com")
Now, invoke (3) and the definition of the
-inner product to write ![\[\expect[f(x_0)f(x_n)] = \sum_{i=1}^m f(i) (P^n f)(i) \pi_i = \langle f, P^n f\rangle.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-10a769b03dee2b18b03876d46eaac7c7_l3.png "Rendered by QuickLaTeX.com")
![\[\expect[f(x_0)f(x_n)] = \left\langle \sum_{i=1}^m c_i \varphi_i,\sum_{i=1}^m c_i P^n\varphi_i \right\rangle = \left\langle \sum_{i=1}^m c_i \varphi_i,\sum_{i=1}^m c_i \lambda_i^n \varphi_i \right\rangle = \sum_{i=1}^m \lambda_i^n \, c_i^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-63bbc0c0f98d4c57de9a53a7162295f3_l3.png "Rendered by QuickLaTeX.com")
Combining this formula with our earlier observation that ![\expect[f(x_0)] = \expect[f(x_n)] = c_1](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0dee583b20d0c65301633cb289069661_l3.png "Rendered by QuickLaTeX.com") and plugging into (4), we obtain
and plugging into (4), we obtain
(5) ![\[\Cov(f(x_0),f(x_n)) = \sum_{i=1}^m \lambda_i^n \, c_i^2 - c_1^2 = \sum_{i=2}^m \lambda_i^n c_i^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-20b7af4f300077ae2d041dae30de529d_l3.png "Rendered by QuickLaTeX.com")
 , so
, so  entirely drops out of the covariance.
entirely drops out of the covariance.
Step 4: Wrapping it Up
With the formula (5) for the covariance in hand, we are ready to evaluate the variance parameter in the Markov chain CLT. First, note that the variance is
![\[\Var[f(x_0)] = \Cov(f(x_0),f(x_0)) = \sum_{i=2}^m \lambda_i^0 c_i^2 = \sum_{i=2}^m c_i^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5f587d4d05f65d8d43d5824fd499d0d2_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*}\sigma^2 &= \Var[f(x_0)] + 2\sum_{n=1}^\infty \Cov(f(x_0),f(x_n)) \\&= \sum_{i=2}^m c_i^2 + 2\sum_{n=1}^\infty \sum_{i=2}^m \lambda_i^n \, c_i^2 \\&= -\sum_{i=2}^m c_i^2 + 2\sum_{i=2}^m \left(\sum_{n=0}^\infty \lambda_i^n\right)c_i^2 .\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-da05968b01086497f8e6e098e384b170_l3.png "Rendered by QuickLaTeX.com")
Now, apply the formula for the sum of an infinite geometric series to obtain
(6) ![\[\sigma^2 = -\sum_{i=2}^m c_i^2 + 2\sum_{i=2}^m \frac{1}{1-\lambda_i} c_i^2 = \sum_{i=2}^m \left(\frac{2}{1-\lambda_i}-1\right)c_i^2 = \sum_{i=2}^m \frac{1+\lambda_i}{1-\lambda_i} c_i^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-61c9cb2ae48b8b474edd697e36a1e58c_l3.png "Rendered by QuickLaTeX.com")
Conclusion: Laziness is (Asymptotically) Bad for Averaging
Before we get to the conclusions, let’s summarize where we are. We are seeking to use Markov chain average
![\[\hat{f}_N = \frac{1}{N} \sum_{i=0}^{N-1} f(x_n)\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-76330a2c8101f63831cdc0bcdd4e0cee_l3.png "Rendered by QuickLaTeX.com")
![\expect_{x \sim \pi} [f(x)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c4b525a230a1b1912a79546d8b641e00_l3.png "Rendered by QuickLaTeX.com") . The Markov chain central limit theorem shows that, for a large number of steps , the error
. The Markov chain central limit theorem shows that, for a large number of steps , the error ![\hat{f}_N - \expect_{x\sim\pi}[f(x)]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0f260b35378f3e3cb9ca1723ad1a0fe1_l3.png "Rendered by QuickLaTeX.com") is approximately normally distributioned with mean zero and variance . So to obtain accurate estimates, we want to be as small as possible.
is approximately normally distributioned with mean zero and variance . So to obtain accurate estimates, we want to be as small as possible.
After some work, we were able to derive a formula (6) for in terms of the eigenvalues  of the transition matrix . The formula for for the lazy chain is identical, except with each eigenvalue replaced by
of the transition matrix . The formula for for the lazy chain is identical, except with each eigenvalue replaced by  . Thus, we have
. Thus, we have

From these formulas, it is clear that the lazy Markov chain has a larger
parameter and is thus less accurate than the non-lazy Markov chain, no matter what the eigenvalues are.
To compare the non-lazy and lazy chains in another way, consider the plot below. The blue solid line shows the amplification factor  of an eigenvalue , which represents amount by which the squared coefficient
of an eigenvalue , which represents amount by which the squared coefficient  is scaled by in . In the red-dashed line, we see the corresponding amplification factor
is scaled by in . In the red-dashed line, we see the corresponding amplification factor  for the corresponding eigenvalue
for the corresponding eigenvalue  of the lazy chain. We see that at every
of the lazy chain. We see that at every  value, the lazy chain has a higher amplification factor than the original chain.
value, the lazy chain has a higher amplification factor than the original chain.
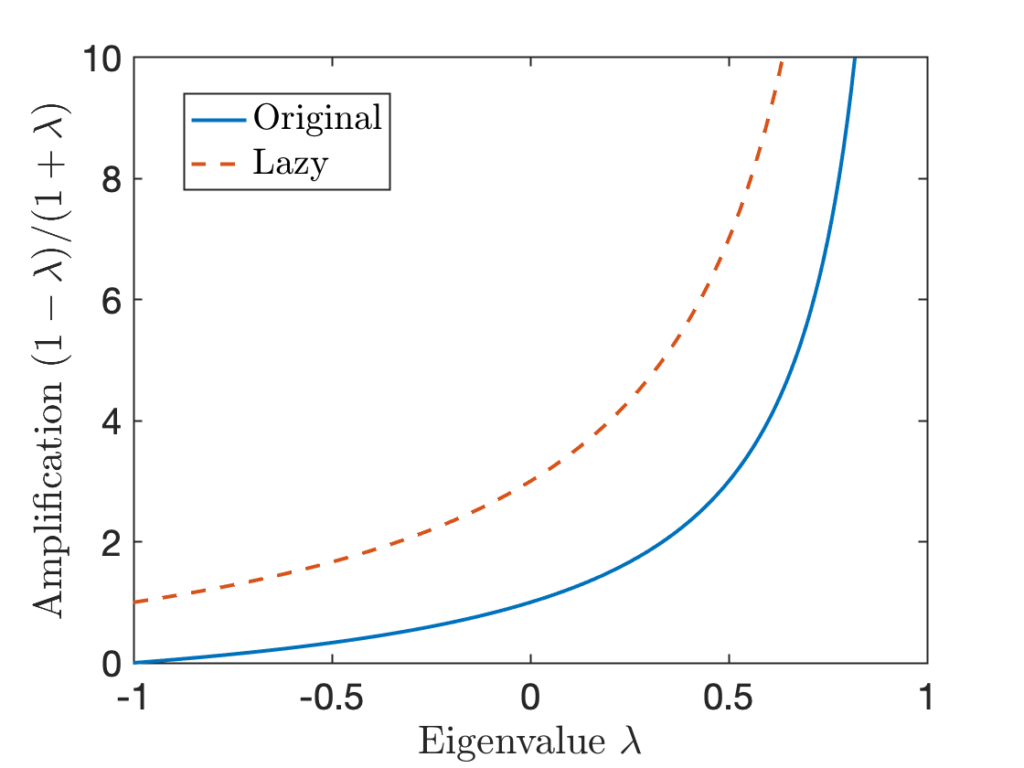
Remember that our original motivation for using the lazy chain was to remove the possibility of slow convergence of the chain to stationarity because of negative eigenvalues. But for the averaging application, negative eigenvalues are great. The process of Markov chain averaging shrinks the influence of negative eigenvalues on , whereas positive eigenvalues are amplified. For the averaging application, negative eigenvalues for the chain are a feature, not a bug.
Moral of the Story
Much of Markov chain theory, particularly in theoretical parts of computer science, mathematics, and machine learning, is centered around proving convergence to stationarity. Negative eigenvalues are a genuine obstruction to convergence to stationarity, and using the lazy chain in practice may be a sensible idea if one truly needs a sample from the stationary distribution in a given application.
But one-shot sampling is not the only or even the most common uses for Markov chains in computational practice. For other applications, such as averaging, the negative eigenvalues are actually a help. Using the lazy chain in practice for these problems would be a poor idea.
To me, the broader lesson in this story is that, as applied mathematicians, it can be inadvisable to become too fixated on one particular mathematical benchmark for designing and analyzing algorithms. Proving rapid convergence to stationarity with respect to the total variation distance is one nice way to analyze Markov chains. But it isn’t the only way, and chains not possessing this property because of large negative eigenvalues may actually be better in practice for some problems. Ultimately, applied mathematics should, at least in part, be guided by applications, and paying attention to how algorithms are used in practice should inform how we build and evaluate new ones.
One thought on “Markov Musings 4: Should You Be Lazy?”