In the previous post, we looked at the randomized SVD. In this post, we continue this discussion by looking at the analysis of the randomized SVD. Our approach is adapted from a new analysis of the randomized SVD by Joel A. Tropp and Robert J. Webber.
There are many types of analysis one can do for the randomized SVD. For instance, letting  be a matrix and
be a matrix and  the rank-
the rank- output of the randomized SVD, natural questions include:
output of the randomized SVD, natural questions include:
- What is the expected error
 measured in some norm
measured in some norm  ? What about expected squared error
? What about expected squared error  ? How do these answers change with different norms?
? How do these answers change with different norms? - How large can the randomized SVD error
 get except for some small failure probability
get except for some small failure probability  ?
? - How close is the randomized SVD truncated to rank
 compared to the best rank- approximation to ?
compared to the best rank- approximation to ? - How close are the singular values and vectors of the randomized SVD approximation compared to those of ?
Implicitly and explicitly, the analysis of Tropp and Webber provides satisfactory answers to a number of these questions. In the interest of simplifying the presentation, we shall focus our presentation on just one of these questions, proving following result:
![\[\mathbb{E} \left\|B-X\right\|_{\rm F}^2 \le \left( 1 + \frac{k}{k-(r+1)}\right) \left\|B - \lowrank{B}_r \right\|_{\rm F}^2 \quad \text{for every $r \le k-2$}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-6759ab11982f765f19dc615fb8e1fbdc_l3.png "Rendered by QuickLaTeX.com")
Here,  is the Frobenius norm. We encourage the interested reader to check out Tropp and Webber’s paper to see the methodology we summarize here used to prove numerous facts about the randomized SVD and its extensions using subspace iteration and block Krylov iteration.
is the Frobenius norm. We encourage the interested reader to check out Tropp and Webber’s paper to see the methodology we summarize here used to prove numerous facts about the randomized SVD and its extensions using subspace iteration and block Krylov iteration.
Projection Formula
Let us recall the randomized SVD as we presented it in last post:
- Collect information. Form
 where
where  is an appropriately chosen
is an appropriately chosen  random matrix.
random matrix. - Orthogonalize. Compute an orthonormal basis
 for the column space of
for the column space of  by, e.g., thin QR factorization.
by, e.g., thin QR factorization. - Project. Form
 , where
, where  denotes the conjugate transpose.
denotes the conjugate transpose.
The randomized SVD is the approximation
![\[B\approx X \coloneqq QC.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-dbf0ef5be3e2a7fc39d609f4621d2dbd_l3.png "Rendered by QuickLaTeX.com")
It is easy to upgrade  into a compact SVD form
into a compact SVD form  , as we did as steps 4 and 5 in the previous post.
, as we did as steps 4 and 5 in the previous post.
For the analysis of the randomized SVD, it is helpful to notice that the approximation takes the form
![\[X = QC = QQ^*B = \Pi_{B\Omega} B.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0d1ae78fbe7d6d4d91b567795bd91f57_l3.png "Rendered by QuickLaTeX.com")
Here,  denotes the orthogonal projection onto the column space of the matrix
denotes the orthogonal projection onto the column space of the matrix  . We call
. We call  the projection formula for the randomized SVD.1This formula bares a good deal of similarity to the projection formula for the Nyström approximation. This is not a coincidence.
the projection formula for the randomized SVD.1This formula bares a good deal of similarity to the projection formula for the Nyström approximation. This is not a coincidence.
Aside: Quadratic Unitarily Invariant Norms
To state our error bounds in the most general language, we can adopt the language of quadratic unitarily invariant norms. Recall that a square matrix  is unitary if
is unitary if
![\[U^*U = UU^* = I.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-33fedf7ef9e12832ea6188011e3874bd_l3.png "Rendered by QuickLaTeX.com")
You may recall from my post on Nyström approximation that a norm  on matrices is unitarily invariant if
on matrices is unitarily invariant if
![\[\left\|UBV\right\|_{\rm UI} = \left\|B\right\|_{\rm UI} \quad \text{for all unitary matrices $U$, $V$ and any matrix $B$}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5fd16f43277f7e25ee2f910665984e09_l3.png "Rendered by QuickLaTeX.com")
A unitarily invariant norm  is said to be quadratic if there exists another unitarily invariant norm such that
is said to be quadratic if there exists another unitarily invariant norm such that
(1) ![\[\left\|B\right\|_{\rm Q}^2 = \left\|B^*B\right\|_{\rm UI} = \left\|BB^*\right\|_{\rm UI} \quad \text{for every matrix $B$.} \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-aac3c6aec691fb438adf6690682d855d_l3.png "Rendered by QuickLaTeX.com")
Many examples of quadratic unitarily invariant norms are found among the Schatten  -norms, defined as
-norms, defined as
![\[\left\|B\right\|_{S_p}^p \coloneqq \sum_i \sigma_i(B)^p.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d032386a33d5df74c8a44235dafac359_l3.png "Rendered by QuickLaTeX.com")
Here,  denote the decreasingly order singular values of . The Schatten
denote the decreasingly order singular values of . The Schatten  -norm
-norm  is the Frobenius norm of a matrix. The spectral norm (i.e., operator 2-norm) is the Schatten
is the Frobenius norm of a matrix. The spectral norm (i.e., operator 2-norm) is the Schatten  -norm, defined to be
-norm, defined to be
![\[\norm{B} = \left\|B\right\|_{S_\infty} \coloneqq \max_i \sigma_i(B) = \sigma_1(B).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-584051e6c083d9b865ffe52d79186a00_l3.png "Rendered by QuickLaTeX.com")
The Schatten -norms are unitarily invariant norms for every  . However, the Schatten -norms are quadratic unitarily invariant norms only for
. However, the Schatten -norms are quadratic unitarily invariant norms only for  since
since
![\[\left\|B\right\|_{S_p}^2 = \left\|B^*B\right\|_{S_{p/2}}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-27e888ecff0b0c38df6e73a803f8aa1d_l3.png "Rendered by QuickLaTeX.com")
For the remainder of this post, we let and be a quadratic unitarily invariant norm pair satisfying (1).
Error Decomposition
The starting point of our analysis is the following decomposition of the error of the randomized SVD:
(2) ![\[\left\|B - X\right\|_{\rm Q}^2 \le \left\|B - \lowrank{B}_r\right\|_{\rm Q}^2 + \left\|\lowrank{B}_r - \Pi_{B\Omega} \lowrank{B}_r\right\|_{\rm Q}^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-c1738a10a5c46d5455b8e2d5992ce98d_l3.png "Rendered by QuickLaTeX.com")
Recall that we have defined  to be an optimal rank-
to be an optimal rank- approximation to :
approximation to :
![\[\left\|B - \lowrank{B\right\|_r}_{\rm Q} \le \left\|B - C\right\|_{\rm Q} \quad \text{for any rank-$r$ matrix $C$}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-46106e1ebeaa349721ea4e81d171f70b_l3.png "Rendered by QuickLaTeX.com")
Thus, the error decomposition says that the excess error is bounded by
![\[\left\|B - X\right\|_{\rm Q}^2 - \left\|B - \lowrank{B}_r\right\|_{\rm Q}^2 \le \left\|\lowrank{B}_r - \Pi_{B\Omega} \lowrank{B}_r\right\|_{\rm Q}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e44e6de74ec072bf3d6c944ea6de77db_l3.png "Rendered by QuickLaTeX.com")
Using the projection formula, we can prove the error decomposition (2) directly:

The first line is the projection formula, the second is relation between  and
and  , and the third is the triangle inequality. For the fifth line, we use the fact that
, and the third is the triangle inequality. For the fifth line, we use the fact that  is an orthoprojector and thus has unit spectral norm
is an orthoprojector and thus has unit spectral norm  together with the fact that
together with the fact that
![\[\left\|BCD\right\|_{\rm UI} \le \norm{B} \cdot \left\|C\right\|_{\rm UI}\cdot \norm{D} \quad \text{for all matrices $B,C,D$.}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e329f332e4305af288668bfdf1ab4bf5_l3.png "Rendered by QuickLaTeX.com")
For the final inequality, we used commutation rule
![\[(B - \lowrank{B}_r)(B - \lowrank{B}_r)^* = BB^* - \lowrank{B}_r\lowrank{B}_r^*.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9db3f7e6eb57261b556783a0a7d62fd0_l3.png "Rendered by QuickLaTeX.com")
Bounding the Error
In this section, we shall continue to refine the error decomposition (2). Consider a thin SVD of , partitioned as
![\[B = \onebytwo{U_1}{U_2} \twobytwo{\Sigma_1}{0}{0}{\Sigma_2}\onebytwo{V_1}{V_2}^*\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-54a749c18b5a76a0f468adee8b5fa58f_l3.png "Rendered by QuickLaTeX.com")
where
 and
and  both have orthonormal columns,
both have orthonormal columns, and
and  are square diagonal matrices with nonnegative entries,
are square diagonal matrices with nonnegative entries, and
and  have columns, and
have columns, and- is an
 matrix.
matrix.
Under this notation, the best rank- approximation is  . Define
. Define
![\[\twobyone{\Omega_1}{\Omega_2} \coloneqq \twobyone{V_1^*}{V_2^*} \Omega.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f620ec79bd8a3f6022efb5ca07b0d824_l3.png "Rendered by QuickLaTeX.com")
We assume throughout that  is full-rank (i.e.,
is full-rank (i.e.,  ).
).
Applying the error decomposition (2), we get
(3) 
For the second line, we used the unitary invariance of . Observe that the column space of is a superset of the column space of  so
so
(4) ![\[\norm{(I-\Pi_{B\Omega})U_1\Sigma_1}_{\rm Q}^2 \le \norm{(I-\Pi_{B\Omega\Omega_1^\dagger})U_1\Sigma_1}_{\rm Q}^2 = \norm{\Sigma_1U_1^*(I-\Pi_{B\Omega\Omega_1^\dagger})U_1\Sigma_1}_{\rm UI}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2fdd85edd3e561ae5496031960d8901a_l3.png "Rendered by QuickLaTeX.com")
Let’s work on simplifying the expression
![\[\Sigma_1U_1^*(I-\Pi_{B\Omega\Omega_1^\dagger})U_1\Sigma_1.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f21f88902abb8532d54b098fa358ddc0_l3.png "Rendered by QuickLaTeX.com")
First, observe that
![\[B\Omega\Omega_1^\dagger = B\onebytwo{V_1}{V_2}\twobyone{\Omega_1}{\Omega_2}\Omega_1^\dagger = \onebytwo{U_1}{U_2} \twobytwo{\Sigma_1}{0}{0}{\Sigma_2} \twobyone{I}{\Omega_2\Omega_1^\dagger} = U_1\Sigma_1 + U_2\Sigma_2\Omega_2\Omega_1^\dagger.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e1dbcff75c12101b6274492896899b52_l3.png "Rendered by QuickLaTeX.com")
Thus, the projector  takes the form
takes the form
![\begin{align*}\Pi_{B\Omega\Omega_1^\dagger} &= (B\Omega\Omega_1^\dagger) \left[(B\Omega\Omega_1^\dagger)^*(B\Omega\Omega_1^\dagger)\right]^\dagger (B\Omega\Omega_1^\dagger)^* \\&= (U_1\Sigma_1 + U_2\Sigma_2\Omega_2\Omega_1^\dagger) \left[\Sigma_1^2 + (\Sigma_2\Omega_2\Omega_1^\dagger)^*(\Sigma_2\Omega_2\Omega_1^\dagger)\right]^\dagger (U_1\Sigma_1 + U_2\Sigma_2\Omega_2\Omega_1^\dagger)^*.\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d9e0cd585357787c460f6471f52ecb0a_l3.png "Rendered by QuickLaTeX.com")
Here,  denotes the Moore–Penrose pseudoinverse, which reduces to the ordinary matrix inverse for a square nonsingular matrix. Thus,
denotes the Moore–Penrose pseudoinverse, which reduces to the ordinary matrix inverse for a square nonsingular matrix. Thus,
(5) ![\[\Sigma_1U_1^*(I-\Pi_{B\Omega\Omega_1^\dagger})U_1\Sigma_1 = \Sigma_1^2 - \Sigma_1^2 \left[\Sigma_1^2 + (\Sigma_2\Omega_2\Omega_1^\dagger)^*(\Sigma_2\Omega_2\Omega_1^\dagger)\right]^\dagger\Sigma_1^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b7dfa3f3cbcda5380b6b7ec0132fca2a_l3.png "Rendered by QuickLaTeX.com")
Remarkably, this seemingly convoluted combination of matrices actually is a well-studied operation in matrix theory, the parallel sum. The parallel sum of positive semidefinite matrices  and
and  is defined as
is defined as
(6) ![\[A : H \coloneqq A - A(A+H)^\dagger A. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-0ca6dd2810aa560e0d59d808c9b40bc8_l3.png "Rendered by QuickLaTeX.com")
We will have much more to say about the parallel sum soon. For now, we use this notation to rewrite (5) as
![\[\Sigma_1U_1^*(I-\Pi_{B\Omega\Omega_1^\dagger})U_1\Sigma_1 = \Sigma_1^2 : [(\Sigma_2\Omega_2\Omega_1^\dagger)^*(\Sigma_2\Omega_2\Omega_1^\dagger)].\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-dc620e38c4fb8a7855e330183c8313c9_l3.png "Rendered by QuickLaTeX.com")
Plugging this back into (4) and then (3), we obtain the error bound
(7) ![\[\left\|B - X\right\|_{\rm Q}^2\le \left\| \Sigma_2 \right\|_{\rm Q}^2 + \left\|\Sigma_1^2 : [(\Sigma_2\Omega_2\Omega_1^\dagger)^*(\Sigma_2\Omega_2\Omega_1^\dagger)]\right\|_{\rm UI}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-ff8a161c38344c97e0d615d216d4555d_l3.png "Rendered by QuickLaTeX.com")
Simplifying this expression further will require more knowledge about parallel sums, which we shall discuss now.
Aside: Parallel Sums
Let us put aside the randomized SVD for a moment and digress to the seemingly unrelated topic of electrical circuits. Suppose we have a battery of voltage  and we connect the ends using a wire of resistance
and we connect the ends using a wire of resistance  . The current
. The current  is given by Ohm’s law
is given by Ohm’s law
![\[v = a \cdot \mathrm{curr}_a.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-50ff6a1f099e535f6dfd8525f45b4741_l3.png "Rendered by QuickLaTeX.com")
Similarly, if the wire is replaced by a different wire with resistance  , the current
, the current  is then
is then
![\[v = h \cdot \mathrm{curr}_h.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-baea64abba5be2425a04d7d2316f7153_l3.png "Rendered by QuickLaTeX.com")
Now comes the interesting question. What if we connect the battery by both wires (resistances and ) simultaneously in parallel, so that current can flow through either wire? Since wires of resistances and still have voltage , Ohm’s law still applies and thus the total current is
![\[\mathrm{curr}_{\rm total} = \mathrm{curr}_a + \mathrm{curr}_h = \frac{v}{a} + \frac{v}{h} = v \left(a^{-1}+h^{-1}\right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-2ce6cd66280641977f8eea4d3d9f6cab_l3.png "Rendered by QuickLaTeX.com")
The net effect of connecting resisting wires of resistances and is the same as a single resisting wire of resistance
(8) ![\[a:h \coloneqq \frac{v}{\mathrm{curr}_{\rm total}} = \left( a^{-1}+h^{-1}\right)^{-1}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-46eba66bdf328c974e763d8c43422e75_l3.png "Rendered by QuickLaTeX.com")
We call the the operation  the parallel sum of and because it describes how resistances combine when connected in parallel.
the parallel sum of and because it describes how resistances combine when connected in parallel.
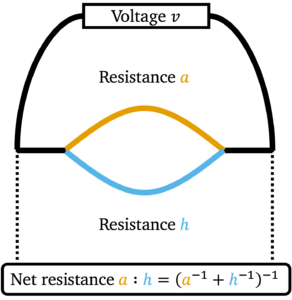
The parallel sum operation  can be extended to all nonnegative numbers and by continuity:
can be extended to all nonnegative numbers and by continuity:
![\[a:h \coloneqq \lim_{b\downarrow a, \: k\downarrow h} b:k = \begin{cases}\left( a^{-1}+h^{-1}\right)^{-1}, & a,h > 0 ,\\0, & \textrm{otherwise}.\end{cases}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7c49cbcbcd8d8f75fa4f18a40562e718_l3.png "Rendered by QuickLaTeX.com")
Electrically, this definition states that one obtains a short circuit (resistance  ) if either of the wires carries zero resistance.
) if either of the wires carries zero resistance.
Parallel sums of matrices were introduced by William N. Anderson, Jr. and Richard J. Duffin as a generalization of the parallel sum operation from electrical circuits. There are several equivalent definitions. The natural definition (8) applies for positive definite matrices
![\[A:H = (A^{-1}+H^{-1})^{-1} \quad \text{for $A,H$ positive definite.}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-95cd7707ba37e3436926c73895d537bb_l3.png "Rendered by QuickLaTeX.com")
This definition can be extended to positive semidefinite matrices by continuity. It can be useful to have an explicit definition which applies even to positive semidefinite matrices. To do so, observe that the (scalar) parallel sum satisfies the identity
![\[a:h = \frac{1}{a^{-1}+h^{-1}} = \frac{ah}{a+h} = \frac{a(a+h)-a^2}{a+h} = a - a(a+h)^{-1}a.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e4e355840ccdeb857cec59c1173cca5b_l3.png "Rendered by QuickLaTeX.com")
To extend to matrices, we capitalize the letters and use the Moore–Penrose pseudoinverse in place of the inverse:
![\[A : H = A - A(A+H)^\dagger A.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-85f7337339efbd593339ed3a5ff7e547_l3.png "Rendered by QuickLaTeX.com")
This was the definition (6) of the parallel sum we gave above which we found naturally in our randomized SVD error bounds.
The parallel sum enjoys a number of beautiful properties, some of which we list here:
- Symmetry.
 ,
, - Simplified formula.
 for positive definite matrices,
for positive definite matrices, - Bounds.
 and
and  .
. - Monotone.
 is monotone in the Loewner order.
is monotone in the Loewner order. - Concavity. The map
 is (jointly) concave (with respect to the Loewner order).
is (jointly) concave (with respect to the Loewner order). - Conjugation. For any square
 ,
,  .
. - Trace.
 .
.
For completionists, we include a proof of the last property for reference.
 be the unitarily invariant norm dual to .2Dual with respect to the Frobenius inner product, that is. By duality, we have
be the unitarily invariant norm dual to .2Dual with respect to the Frobenius inner product, that is. By duality, we have ![\begin{align*}\left\|A:H\right\|_{\rm UI} &= \max_{M\succeq 0,\: \left\|M\right\|_{\rm UI}'\le 1} \tr((A:H)M) \\&= \max_{M\succeq 0,\: \left\|M\right\|_{\rm UI}'\le 1} \tr(M^{1/2}(A:H)M^{1/2})\\&= \max_{M\succeq 0,\: \left\|M\right\|_{\rm UI}'\le 1} \tr((M^{1/2}AM^{1/2}):(M^{1/2}HM^{1/2})) \\&\le \max_{M\succeq 0,\: \left\|M\right\|_{\rm UI}'\le 1} \left[\tr(M^{1/2}AM^{1/2}):\tr(M^{1/2}HM^{1/2}) \right] \\&\le \left[\max_{M\succeq 0,\: \left\|M\right\|_{\rm UI}'\le 1} \tr(M^{1/2}AM^{1/2})\right]:\left[\max_{M\succeq 0,\: \left\|M\right\|_{\rm UI}'\le 1} \tr(M^{1/2}HM^{1/2})\right]\\&= \left\|A\right\|_{\rm UI} : \left\|H\right\|_{\rm UI}.\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4d5c2226a0ddf81d346da401ff4b53b9_l3.png "Rendered by QuickLaTeX.com")
The first line is duality, the second holds because
 , the third line is property 6, the fourth line is property 7, the fifth line is property 4, and the sixth line is duality.
, the third line is property 6, the fourth line is property 7, the fifth line is property 4, and the sixth line is duality.Nearing the Finish: Enter the Randomness
Equipped with knowledge about parallel sums, we are now prepared to return to bounding the error of the randomized SVD. Apply property 8 of the parallel sum to the randomized SVD bound (7) to obtain
![\begin{align*}\left\|B - X\right\|_{\rm Q}^2&\le \left\| \Sigma_2 \right\|_{\rm Q}^2 + \left\|\Sigma_1^2 : [(\Sigma_2\Omega_2\Omega_1^\dagger)^*(\Sigma_2\Omega_2\Omega_1^\dagger)]\right\|_{\rm UI} \\&\le \left\| \Sigma_2 \right\|_{\rm Q}^2 + \left\|\Sigma_1^2\right\|_{\rm UI} : \left\|[(\Sigma_2\Omega_2\Omega_1^\dagger)^*(\Sigma_2\Omega_2\Omega_1^\dagger)]\right\|_{\rm UI} \\&= \left\| \Sigma_2 \right\|_{\rm Q}^2 + \left\|\Sigma_1\right\|_{\rm Q}^2 : \left\|\Sigma_2\Omega_2\Omega_1^\dagger\right\|^2_{\rm Q}.\end{align*}](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-df07b0b9660af51129fd29552ad6c650_l3.png "Rendered by QuickLaTeX.com")
This bound is totally deterministic: It holds for any choice of test matrix , random or otherwise. We can use this bound to analyze the randomized SVD in many different ways for different kinds of random (or non-random) matrices . Tropp and Webber provide a number of examples instantiating this general bound in different ways.
We shall present only the simplest error bound for randomized SVD. We make the following assumptions:
- The test matrix is standard Gaussian.
Under these assumptions and using the property  , we obtain the following expression for the expected error of the randomized SVD
, we obtain the following expression for the expected error of the randomized SVD
(9) ![\[\mathbb{E} \left\|B - X\right\|_{\rm F}^2\le \left\| B - \lowrank{B\right\|_r }_{\rm F}^2 + \mathbb{E}\left\|\Sigma_2\Omega_2\Omega_1^\dagger\right\|^2_{\rm F}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3f9645663663b82d968efe393fc4c158_l3.png "Rendered by QuickLaTeX.com")
All that is left to is compute the expectation of  . Remarkably, this can be done in closed form.
. Remarkably, this can be done in closed form.
Aside: Expectation of Gaussian–Inverse Gaussian Matrix Product
The final ingredient in our randomized SVD analysis is the following computation involving Gaussian random matrices. Let  and
and  be independent standard Gaussian random matrices with of size
be independent standard Gaussian random matrices with of size  ,
,  . Then
. Then
![\[\mathbb{E} \left\|SG\Gamma^\dagger R\right\|_{\rm F}^2 = \frac{1}{k-(r+1)}\left\|S\right\|_{\rm F}^2\left\|R\right\|_{\rm F}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-83f5771c01f2d031fd755830d363cda0_l3.png "Rendered by QuickLaTeX.com")
For the probability lovers, we will now go on to prove this. For those who are less probabilistically inclined, this result can be treated as a black box.
 does not appear:
does not appear: ![\[\mathbb{E} \left\|SGW\right\|_{\rm F}^2 = \mathbb{E} \sum_{ij} \left(\sum_{k\ell} s_{ik}g_{k\ell}w_{\ell j} \right)^2 = \mathbb{E} \sum_{ijk\ell} s_{ik}^2 w_{\ell j}^2 = \left\|S\right\|_{\rm F}^2\left\|W\right\|_{\rm F}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-dc219fd0dab2748965ecbf439c051db5_l3.png "Rendered by QuickLaTeX.com")
Here, we used the fact that the entries
 are independent, mean-zero, and variance-one. Thus, applying this result conditionally on with
are independent, mean-zero, and variance-one. Thus, applying this result conditionally on with  , we get
, we get (10) ![\[\mathbb{E} \left\|SG\Gamma^\dagger R\right\|_{\rm F}^2 =\mathbb{E}\left[ \mathbb{E}\left[ \left\|SG\Gamma^\dagger R\right\|_{\rm F}^2 \,\middle|\, \Gamma\right]\right] =\left\|S\right\|_{\rm F}^2\cdot \mathbb{E} \left\|\Gamma^\dagger R\right\|_{\rm F}^2. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-31c52f341c1e50d4e2c2e8583f3a7737_l3.png "Rendered by QuickLaTeX.com")
To compute
 , we rewrite using the trace
, we rewrite using the trace ![\[\mathbb{E} \left\|\Gamma^\dagger R\right\|_{\rm F}^2 = \mathbb{E} \tr \left(\Gamma^\dagger RR^* \Gamma^{*\dagger} \right)= \tr \left(RR^* \mathbb{E}[\Gamma^{*\dagger}\Gamma^\dagger] \right) = \tr \left(RR^* \mathbb{E}[(\Gamma\Gamma^*)^{-1}] \right).\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-79bd47bd70f2015a46c038c4f0d0e5f7_l3.png "Rendered by QuickLaTeX.com")
The matrix
 is known as an inverse-Wishart matrix and is a well-studied random matrix model. In particular, its expectation is known to be
is known as an inverse-Wishart matrix and is a well-studied random matrix model. In particular, its expectation is known to be  . Thus, we obtain
. Thus, we obtain ![\[\mathbb{E} \left\|\Gamma^\dagger R\right\|_{\rm F}^2 = \tr \left(RR^* \mathbb{E}[(\Gamma\Gamma^*)^{-1}] \right) = \frac{\tr \left(RR^* \right)}{k-(r+1)} = \frac{\left\|R\right\|_{\rm F}^2}{k-(r+1)}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e874bd74b5ef81c13856de05454ea647_l3.png "Rendered by QuickLaTeX.com")
Plugging into (10), we obtain the desired conclusion
![\[\mathbb{E} \left\|SG\Gamma^\dagger R\right\|_{\rm F}^2 =\left\|S\right\|_{\rm F}^2\cdot \mathbb{E} \left\|\Gamma^\dagger R\right\|_{\rm F}^2 = \frac{1}{k-(r+1)}\left\|S\right\|_{\rm F}^2\left\|R\right\|_{\rm F}^2.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b2ac63d48bafba095409bc148beed39c_l3.png "Rendered by QuickLaTeX.com")
This completes the proof.
Wrapping it All Up
We’re now within striking distance. All that is left is to assemble the pieces we have been working with to obtain a final bound for the randomized SVD.
Recall we have chosen the random matrix to be standard Gaussian. By the rotational invariance of the Gaussian distribution, and  are independent and standard Gaussian as well. Plugging the matrix expectation bound to (9) then completes the analysis
are independent and standard Gaussian as well. Plugging the matrix expectation bound to (9) then completes the analysis

3 thoughts on “Low-Rank Approximation Toolbox: Analysis of the Randomized SVD”