In this post, we’ll talk about Markov chains, a useful and general model of a random system evolving in time.
PageRank
To see how Markov chains can be useful in practice, we begin our discussion with the famous PageRank problem. The goal is assign a numerical ranking to each website on the internet measuring how important it is. To do this, we form a mathematical model of an internet user randomly surfing the web. The importance of each website will be measured by the amount of times this user visits each page.
The PageRank model of an internet user is as follows: Start the user at an arbitrary initial website  . At each step, the user makes one of two choices:
. At each step, the user makes one of two choices:
- With 85% probability, the user follows a random link on their current website.
- With 15% probability, the user gets bored and jumps to a random website selected from the entire internet.
As with any mathematical model, this is a riduculously oversimplified description of how a person would surf the web. However, like any good mathematical model, it is useful. Because of the way the model is designed, the user will spend more time on websites with many incoming links. Thus, websites with many incoming links will be rated as important, which seems like a sensible choice.
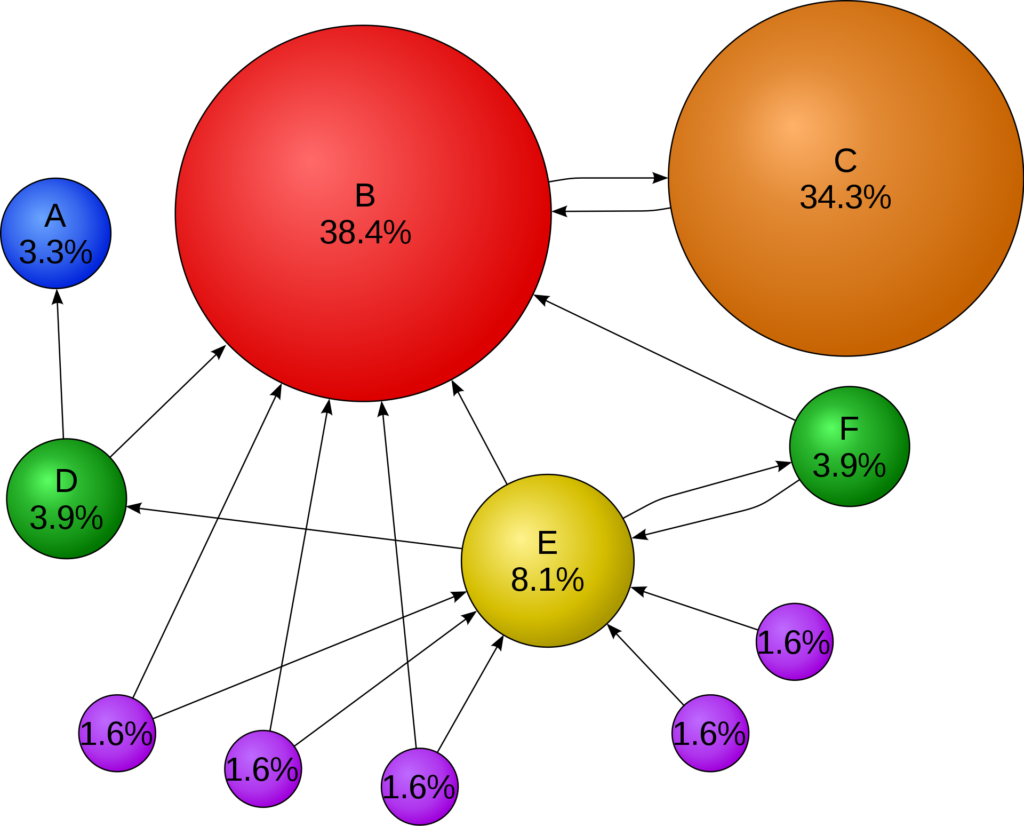
An example of the PageRank distribution for a small internet is shown below. As one would expect, the surfer spends a large part of their time on website B, which has many incoming links. Interestingly, the user spends almost as much of their time on website C, whose only links are to and from B. Under the PageRank model, a website is important if it is linked to by an important website, even if that is the only website linking to it.
Markov Chains in General
Having seen one Markov chain, the PageRank internet surfer, let’s talk about Markov chains in general. A (time-homogeneous) Markov chain consists of two things: a set of states and probabilities for transitioning between states:
- Set of states. For this discussion, we limit ourselves to Markov chains which can only exist in finitely many different states. To simplify our discussion, label the possible states using numbers
 .
. - Transition probabilities. The definining property of a (time-homogeneous) Markov chain is that, at any point in time
 , if the state is
, if the state is  , the probability of moving to state
, the probability of moving to state  is a fixed number
is a fixed number  . In particular, the probability of moving from to does not depend on the time or the past history of the chain before time ; only the value of the chain at time matters.
. In particular, the probability of moving from to does not depend on the time or the past history of the chain before time ; only the value of the chain at time matters.
Denote the state of the Markov chain at times  by
by  . Note that the states are random quantities. We can write the Markov chain property using the language of conditional probability:
. Note that the states are random quantities. We can write the Markov chain property using the language of conditional probability:
![\[\mathbb{P} \{ x_{n+1} = j \mid x_n = i,x_{n-1}=a_{n-1},\ldots,x_0=a_0\} = \mathbb{P}\{x_{n+1} = j \mid x_n = i\} = P_{ij}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d1fa5c29673402a40f530434ec99f998_l3.png "Rendered by QuickLaTeX.com")
This equation states that the probability that the system is in state at time  given the entire history of the system depends only on the value
given the entire history of the system depends only on the value  of the chain at time . This probability is the transition probability .
of the chain at time . This probability is the transition probability .
Let’s see how the PageRank internet surfer fits into this model:
- Set of states. Here, the set of states are the websites, which we label
 .
. - Transition probabilities. Consider two websites and . If does not have a link to , then the only way of going from to is if the surfer randomly gets bored (probability 15%) and picks website to visit at random (probability
 ). Thus,
). Thus, (
Suppose instead that )
) ![\[P_{ij} = \frac{0.15}{m}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e9cb5a0e824c976c19d2d73c1f45714b_l3.png "Rendered by QuickLaTeX.com") does link to and has
does link to and has  outgoing links. Then, in addition to the
outgoing links. Then, in addition to the  probability computed before, user has an 85% percent chance of following a link and a
probability computed before, user has an 85% percent chance of following a link and a  chance of picking as that link. Thus,
chance of picking as that link. Thus, (
 )
) ![\[P_{ij} = \frac{0.85}{d_i} + \frac{0.15}{m}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-51a6f3c00da58822f6465db8458a1f8c_l3.png "Rendered by QuickLaTeX.com")
Markov Chains and Linear Algebra
For a non-random process  , we can understand the processes evolution by determining its state
, we can understand the processes evolution by determining its state  at every point in time . Since Markov chains are random processes, it is not enough to track the state
at every point in time . Since Markov chains are random processes, it is not enough to track the state  of the process at every time . Rather, we must understand the probability distribution of the state at every point in time .
of the process at every time . Rather, we must understand the probability distribution of the state at every point in time .
It is customary in Markov chain theory to represent a probability distribution on the states  by a row vector
by a row vector  .1To really emphasize that probability distributions are row vectors, we shall write them as transposes of column vectors. So
.1To really emphasize that probability distributions are row vectors, we shall write them as transposes of column vectors. So  is a column vector but represents the probability distribution as is a row vector. The th entry
is a column vector but represents the probability distribution as is a row vector. The th entry  stores the probability that the system is in state . Naturally, as is a probability distribution, its entries must be nonnegative (
stores the probability that the system is in state . Naturally, as is a probability distribution, its entries must be nonnegative ( for every ) and add to one (
for every ) and add to one ( ).
).
Let  denote the probability distributions of the states
denote the probability distributions of the states  . It is natural to ask: How are the distributions related to each other? Let’s answer this question.
. It is natural to ask: How are the distributions related to each other? Let’s answer this question.
The probability that  is in state is the th entry of
is in state is the th entry of  :
:
![\[\rho^{(n+1)}_j = \mathbb{P} \{x_{n+1} = j\}\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d8705a90b65f869a58cd432bbc884cfa_l3.png "Rendered by QuickLaTeX.com")
To compute this probability, we break into cases based on the value of the process at time : either  or
or  or … or
or … or  ; only one of these cases can be true at once. When we have an “or” of random events and these events are mutually exclusive (only can be true at once), then the probabilities add:
; only one of these cases can be true at once. When we have an “or” of random events and these events are mutually exclusive (only can be true at once), then the probabilities add:
![\[\rho^{(n+1)}_j = \mathbb{P} \{x_{n+1} = j\} = \sum_{i=1}^m \mathbb{P} \{x_{n+1} = j, x_n = i\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-448c23761c566dc3504d60b57f1ac8d1_l3.png "Rendered by QuickLaTeX.com")
Now we use some conditional probability. The probability that  and is the probability that times the probability that conditional on . That is,
and is the probability that times the probability that conditional on . That is,
![\[\rho^{(n+1)}_j = \sum_{i=1}^m \mathbb{P} \{x_{n+1} = j, x_n = i\} = \sum_{i=1}^m \mathbb{P} \{x_n = i\} \mathbb{P}\{x_{n+1} = j \mid x_n = i\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9b27f4d81b8b51c36f578f7e00017d96_l3.png "Rendered by QuickLaTeX.com")
Now, we can simplify using our definitions. The probability that is just  and the probability of moving from to is . Thus, we conclude
and the probability of moving from to is . Thus, we conclude
![\[\rho_j^{(n+1)} = \sum_{i=1}^m \rho^{(n)}_i P_{ij} .\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1a858376daf68ec5f2d816ef52e66997_l3.png "Rendered by QuickLaTeX.com")
Phrased in the language of linear algebra, we’ve shown
![\[\left(\rho^{(n+1)}\right)^\top = \left(\rho^{(n)}\right)^\top P \quad \text{for any } n = 0,1,2,\ldots.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9ae710d7c26dc66ed497cc8faf34cab3_l3.png "Rendered by QuickLaTeX.com")
That is, if we view the transition probabilities as comprising an  matrix
matrix  , then the distribution at time is obtained by multiplying the distribution at time by transition matrix . In particular, if we iterate this result, we obtain that the distribution at time is given by
, then the distribution at time is obtained by multiplying the distribution at time by transition matrix . In particular, if we iterate this result, we obtain that the distribution at time is given by
![\[\left(\rho^{(n)}\right)^\top = \left(\rho^{(n-1)}\right)^\top P = \left[\left(\rho^{(n-2)}\right)^\top P\right]P = \left(\rho^{(n-2)}\right)^\top P^2 = \cdots = \left(\rho^{(0)}\right)^\top P^n.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-3fddd821b8cdb4b89262b0c72ea68e55_l3.png "Rendered by QuickLaTeX.com")
Thus, the distribution at time is the distribution at time  multiplied by the th power of the transition matrix .
multiplied by the th power of the transition matrix .
Convergence to Stationarity
Let’s go back to our web surfer again. At time , we started our surfer at a particular website, say  . As such, the probability distribution2To keep notation clean going forward, we will drop the transposes off of probability distributions, except when working with them linear algebraically.
. As such, the probability distribution2To keep notation clean going forward, we will drop the transposes off of probability distributions, except when working with them linear algebraically.  at time is concentrated just on website , with no other website having any probability at all. In the first few steps, most of the probability will remain in the vacinity of website , in the websites linked to by and the websites linked to by the websites linked to by and so on. However, as we run the chain long enough, the surfer will have time to widely across the web and the probability distribution will become less and less influenced by the chain’s starting location. This motivates the following definition:
at time is concentrated just on website , with no other website having any probability at all. In the first few steps, most of the probability will remain in the vacinity of website , in the websites linked to by and the websites linked to by the websites linked to by and so on. However, as we run the chain long enough, the surfer will have time to widely across the web and the probability distribution will become less and less influenced by the chain’s starting location. This motivates the following definition:
Definition. A Markov chain satisfies the mixing property if the probability distributions
converge to a single fixed probability distribution
regardless of how the chain is initialized (i.e., independent of the starting distribution
The distribution for a mixing Markov chain is known as a stationary distribution because it does not change under the action of :
(St) ![\[\pi^\top = \pi^\top P. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-daa1101ffcda26584d5f843c12765158_l3.png "Rendered by QuickLaTeX.com")
To see this, recall the recurrence
![\[\left(\rho^{(n+1)}\right)^\top = \left(\rho^{(n)}\right)^\top P,\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-bcbc3e101491a613c1dcb40680a4ef3b_l3.png "Rendered by QuickLaTeX.com")
take the limit as  , and observe that both
, and observe that both  and
and  converge to
converge to  .
.
One of the basic questions in the theory of Markov chains is finding conditions under which the mixing property (or suitable weaker versions of it) hold. To answer this question, we will need the following definition:
A Markov chain is primitive if, after running the chain for some number
![\[\text{There exists $n$ such that, for any $i,j = 1,2,\ldots,m$, } \quad\mathbb{P}\{x_n = j \mid x_0 = i \} = (P^n)_{ij} > 0.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9796d227fdde3830779ea16f255b9b70_l3.png "Rendered by QuickLaTeX.com")
The fundamental theorem of Markov chains is that primitive chains satisfy the mixing property.
Theorem (fundamental theorem of Markov chains). Every primitive Markov chain is mixing. In particular, there exists one and only probability distribution
converge to
Let’s see an example of the fundamental theorem with the PageRank surfer. After  step, there is at least a
step, there is at least a  chance of moving from any website to any other website . Thus, the chain is primitive. Consequently, there is a unique stationary distribution , and the surfer will converge to this stationary distribution regardless of which website they start at.
chance of moving from any website to any other website . Thus, the chain is primitive. Consequently, there is a unique stationary distribution , and the surfer will converge to this stationary distribution regardless of which website they start at.
Going Backwards in Time
Often, it is helpful to consider what would happen if we ran a Markov chain backwards in time. To see why this is an interesting idea, suppose you run website  and you’re interested in where your traffic is coming from. One way of achieving this would be to initialize the Markov chain at and run the chain backwards in time. Rather than asking, “given I’m at now, where would a user go next?”, you ask “given that I’m at now, where do I expect to have come from?”
and you’re interested in where your traffic is coming from. One way of achieving this would be to initialize the Markov chain at and run the chain backwards in time. Rather than asking, “given I’m at now, where would a user go next?”, you ask “given that I’m at now, where do I expect to have come from?”
Let’s formalize this notion a little bit. Consider a primitive Markov chain with stationary distribution . We assume that we initialize this Markov chain in the stationary distribution. That is, we pick  as our initial distribution for . The time-reversed Markov chain
as our initial distribution for . The time-reversed Markov chain  is defined as follows: The probability
is defined as follows: The probability  of moving from to in the time-reversed Markov chain is the probability that I was at state one step previously given that I’m at state now:
of moving from to in the time-reversed Markov chain is the probability that I was at state one step previously given that I’m at state now:
![\[\mathbb{P} \{y_1 = j \mid y_0 = i\} = P^{\rm rev}_{ij} = \mathbb{P} \{ x_0 = j \mid x_1 = i \}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-caeb5343a623f571314596e612b7315d_l3.png "Rendered by QuickLaTeX.com")
To get a nice closed form expression for the reversed transition probabilities , we can invoke Bayes’ theorem:
(Rev) ![\[P^{\rm rev}_{ij} = \mathbb{P} \{ x_0 = j \mid x_1 = i \} = \frac{\mathbb{P} \{x_0 = j\} \mathbb{P} \{x_1 = i \mid x_0 = j\}}{\mathbb{P} \{x_1 = i\}} = \frac{ \pi_j P_{ji}}{\pi_i}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1ffaf13a6eb4a6d8079f1ee0f7501d5d_l3.png "Rendered by QuickLaTeX.com")
The time-reversed Markov chain can be a strange beast. For the reversed PageRank surfer, for instance, follows links “upstream” traveling from the linked site to the linking site. As such, our hypothetical website owner could get a good sense of where their traffic is coming from by initializing the reversed chain  at their website and following the chain one step back.
at their website and following the chain one step back.
Reversible Markov Chains
We now have two different Markov chains: the original and its time-reversal. Call a Markov chain reversible if these processes are the same. That is, if the transition probabilities are the same:
![\[P^{\rm rev}_{ij} = P_{ij} \quad \text{for every } i,j=1,2,\ldots,m.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-4d394cf7f8d6b8a6318c27c3e447403d_l3.png "Rendered by QuickLaTeX.com")
Using our formula (Rev) for the reversed transition probability, the reversibility condition can be written more concisely as
![\[\pi_i P_{ij} = \pi_j P_{ji}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-d6dade4e26238f165b12b7d2891d3a95_l3.png "Rendered by QuickLaTeX.com")
This condition is referred to as detailed balance.3There is an abstruse—but useful—way of reformulating the detailed balance condition. Think of a vector  as defining a function on the set
as defining a function on the set  ,
,  . Letting
. Letting  denote a random variable drawn from the stationary distribution
denote a random variable drawn from the stationary distribution  , we can define a non-standard inner product on
, we can define a non-standard inner product on  :
: ![\langle f, g\rangle_{\pi} \coloneqq \mathbb{E}[f(x) g(x)] = \sum_{i=1}^m \pi_i f(i)g(i)](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-1c871929113a513c08da0e9fa24a8043_l3.png "Rendered by QuickLaTeX.com") . Then the Markov chain is reversible if and only if detailed balance holds if and only if is a self-adjoint operator on when equipped with the non-standard inner product
. Then the Markov chain is reversible if and only if detailed balance holds if and only if is a self-adjoint operator on when equipped with the non-standard inner product  . This more abstract characterization has useful consequences. For instance, by the spectral theorem, the transition matrix of a reversible Markov chain has real eigenvalues and supports a basis of orthonormal eigenvectors (in the inner product). In words, it states that a Markov chain is reversible if, when initialized in the stationary distribution , the flow of probability mass from to (that is,
. This more abstract characterization has useful consequences. For instance, by the spectral theorem, the transition matrix of a reversible Markov chain has real eigenvalues and supports a basis of orthonormal eigenvectors (in the inner product). In words, it states that a Markov chain is reversible if, when initialized in the stationary distribution , the flow of probability mass from to (that is,  ) is equal to the flow of probability mass from to (that is,
) is equal to the flow of probability mass from to (that is,  ).
).
Many interesting Markov chains are reversible. One class of examples are Markov chain models of physical and chemical processes. Since physical laws like classical and quantum mechanics are reversible under time, so too should we expect Markov chain models built from theories to be reversible.
Not every interesting Markov chain is reversible, however. Indeed, except in special cases, the PageRank Markov chain is not reversible. If links to but. does not link to , then the flow of mass from to will be higher than the flow from to .
Before moving on, we note one useful fact about reversible Markov chains. Suppose a reversible, primitive Markov chain satisfies the detailed balance condition with a probability distribution  :
:
![\[\sigma_i P_{ij} = \sigma_j P_{ji}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-f1ef7062af77b1ad2efc526c3db8a63b_l3.png "Rendered by QuickLaTeX.com")
Then  is the stationary distribution of this chain. To see why, we check the stationarity condition
is the stationary distribution of this chain. To see why, we check the stationarity condition  . Indeed, for every ,
. Indeed, for every ,
![\[(\sigma^\top P)_j = \sum_{i=1}^m \sigma_i P_{ij} = \sum_{i=1}^m \sigma_j P_{ji} = \sigma_j.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-81a7b02ba8de821bb56ecee978ec346d_l3.png "Rendered by QuickLaTeX.com")
The second equality is detailed balance and the third equality is just the condition that the sum of the transition probabilities from to each is one. Thus, and is a stationary distribution for . But a primitive chain has only one stationary distribution , so .
Markov Chains as Algorithms
Markov chains are an amazingly flexible tool. One use of Markov chains is more scientific: Given a system in the real world, we can model it by a Markov chain. By simulating the chain or by studying its mathematical properties, we can hope to learn about the system we’ve modeled.
Another use of Markov chains is algorithmic. Rather than thinking of the Markov chain as modeling some real-world process, we instead design the Markov chain to serve a computationally useful end. The PageRank surfer is one example. We wanted to rank the importance of websites, so we designed a Markov chain to achieve this task.
One task we can use Markov chains to solve are sampling problems. Suppose we have a complicated probability distribution , and we want a random sample from —that is, a random quantity  such that
such that  for every . One way to achieve this goal is to design a primitive Markov chain with stationary distribution . Then, we run the chain for a large number of steps and use as an approximate sample from .
for every . One way to achieve this goal is to design a primitive Markov chain with stationary distribution . Then, we run the chain for a large number of steps and use as an approximate sample from .
To design a Markov chain with stationary distribution , it is sufficient to generate transition probabilities such that and satisfy the detailed balance condition. Then, we are guaranteed that is a stationary distribution for the chain. (We also should check the primitiveness condition, but this is often straightforward.)
Here is an effective way of building a Markov chain to sample from a distribution . Suppose that the chain is in state at time , . To choose the next state, we begin by sampling from a proposal distribution  . The proposal distribution can be almost anything we like, as long as it satisfies three conditions:
. The proposal distribution can be almost anything we like, as long as it satisfies three conditions:
- Probability distribution. For every , the transition probabilitie
 add to one:
add to one:  .
. - Bidirectional. If
 , then
, then  .
. - Primitive. The transition probabilities form a primitive Markov chain.
In order to sample from the correct distribution, we can’t just accept every proposal. Rather, given the proposal , we accept with probability
![\[\min \left\{ 1 , \frac{\pi_j T_{ji}}{\pi_i T_{ij}} \right\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-fb8ef7791b1d955015f1300e0eddfb8c_l3.png "Rendered by QuickLaTeX.com")
If we accept the proposal, the next state of our chain is . Otherwise, we stay where we are  . This Markov chain is known as a Metropolis–Hastings sampler.
. This Markov chain is known as a Metropolis–Hastings sampler.
For clarity, we list the steps of the Metropolis–Hastings sampler explicitly:
- Initialize the chain in any state and set
 .
. - Draw a proposal
 with from the proposal distribution,
with from the proposal distribution,  .
. - Compute the acceptance probability
![\[p_{\rm acc} := \min \left\{ 1 , \frac{\pi_j T_{ji}}{\pi_i T_{ij}} \right\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-e34abfe410068f7516cd1c5e50100c3c_l3.png "Rendered by QuickLaTeX.com")
- With probability
 , set
, set  . Otherwise, set
. Otherwise, set  .
. - Set
 and go back to step 2.
and go back to step 2.
To check that is a stationary distribution of the Metropolis–Hastings distribution, all we need to do is check detailed balance. Note that the probability of transitioning from to  under the Metropolis–Hastings sampler is the proposal probability times the acceptance probability:
under the Metropolis–Hastings sampler is the proposal probability times the acceptance probability:
![\[P_{ij} = T_{ij} \cdot \min \left\{ 1 , \frac{\pi_j T_{ji}}{\pi_i T_{ij}} \right\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-8c98e72078f3de5c0de43a1683f5d406_l3.png "Rendered by QuickLaTeX.com")
Detailed balance is confirmed by a short computation4Note that the detailed balance condition for  is always satisfied for any Markov chain
is always satisfied for any Markov chain  .
.
![\[\pi_i P_{ij} = \pi_i T_{ij} \cdot \min \left\{ 1 , \frac{\pi_j T_{ji}}{\pi_i T_{ij}} \right\} = \min \left\{ \pi_i T_{ij} , \pi_j T_{ji} \right\} = \pi_j P_{ji}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-9ec53c4f48f0cc7bb8cc1d0cd58750f1_l3.png "Rendered by QuickLaTeX.com")
Thus the Metropolis–Hastings sampler has as stationary distribution.
Determinatal Point Processes: Diverse Items from a Collection
The uses of Markov chains in science, engineering, math, computer science, and machine learning are vast. I wanted to wrap up with one application that I find particularly neat.
Suppose I run a bakery and I sell  different baked goods. I want to pick out
different baked goods. I want to pick out  special items for a display window to lure customers into my store. As a first approach, I might pick my top- selling items for the window. But I realize that there’s a problem. All of my top sellers are muffins, so all of the items in my display window are muffins. My display window is doing a good job luring in muffin-lovers, but a bad job of enticing lovers of other baked goods. In addition to rating the popularity of each item, I should also promote diversity in the items I select for my shop window.
special items for a display window to lure customers into my store. As a first approach, I might pick my top- selling items for the window. But I realize that there’s a problem. All of my top sellers are muffins, so all of the items in my display window are muffins. My display window is doing a good job luring in muffin-lovers, but a bad job of enticing lovers of other baked goods. In addition to rating the popularity of each item, I should also promote diversity in the items I select for my shop window.
Here’s a creative solution to my display case problems using linear algebra. Suppose that, rather than just looking at a list of the sales of each item, I define a matrix  for my baked goods. In the
for my baked goods. In the  th entry
th entry  of my matrix, I write the number of sales for baked good . I populate the off-diagonal entries
of my matrix, I write the number of sales for baked good . I populate the off-diagonal entries  of my matrix with a measure of similarity between items and .5There are many ways of defining such a similarity matrix. Here is one way. Let
of my matrix with a measure of similarity between items and .5There are many ways of defining such a similarity matrix. Here is one way. Let  be the number ordered for each bakery item by a random customer. Set
be the number ordered for each bakery item by a random customer. Set  to be the correlation matrix of the random variables , with
to be the correlation matrix of the random variables , with  being the correlation between the random variables
being the correlation between the random variables  and
and  . The matrix has all ones on its diagonal. The off-diagonal entries measure the amount that items and tend to be purchased together. Let
. The matrix has all ones on its diagonal. The off-diagonal entries measure the amount that items and tend to be purchased together. Let  be a diagonal matrix where
be a diagonal matrix where  is the total sales of item . Set
is the total sales of item . Set  . By scaling by the diagonal matrix , the diagonal entries of represent the popularity of each item, whereass the off-diagonal entries still represent correlations, now scaled by popularity. So if and are both muffins, will be large. But if is a muffin and is a cookie, then will be small. For mathematical reasons, we require to be symmetric and positive definite.
. By scaling by the diagonal matrix , the diagonal entries of represent the popularity of each item, whereass the off-diagonal entries still represent correlations, now scaled by popularity. So if and are both muffins, will be large. But if is a muffin and is a cookie, then will be small. For mathematical reasons, we require to be symmetric and positive definite.
To populate my display case, I choose a random subset of items from my full menu of size according to the following strange probability distribution: The probability  of picking items
of picking items  is proportional to the determinant of the submatrix
is proportional to the determinant of the submatrix  . More specifically,
. More specifically,
(-DPP) ![\[\pi_S = \frac{\det A(S,S)}{\sum_{\text{all subsets $T$ of size $k$}} \det A(T,T)}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-26714c8980fc33f439de8cf1e5a692eb_l3.png "Rendered by QuickLaTeX.com")
Here, we let denote the  submatrix of consisting of the entries appearing in rows and columns
submatrix of consisting of the entries appearing in rows and columns  . Such a random subset is known as a -determinantal point process (-DPP). (See this survey for more about DPPs.)
. Such a random subset is known as a -determinantal point process (-DPP). (See this survey for more about DPPs.)
To see why this makes any sense, let’s consider a simple example of  items and a display case of size
items and a display case of size  . Suppose I have three items: a pumpkin muffin, a chocolate chip muffin, and an oatmeal raisin cookies. Say the matrix looks like
. Suppose I have three items: a pumpkin muffin, a chocolate chip muffin, and an oatmeal raisin cookies. Say the matrix looks like
![\[A = \begin{bmatrix} 10 & 9 & 0 \\ 9 & 10 & 0 \\ 0 & 0 & 5 \end{bmatrix}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-b8bb20f6bff68d835397eabaf8a1cdc0_l3.png "Rendered by QuickLaTeX.com")
We see that both muffins are equally popular  and much more popular than the cookie
and much more popular than the cookie  . However, the two muffins are similar to each other and thus the corresponding submatrix has small determinant
. However, the two muffins are similar to each other and thus the corresponding submatrix has small determinant
![\[\det A(\{1,2\},\{1,2\}) = \det \twobytwo{10}{9}{9}{10} = 19.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-7f74f9426bb0c808b9e4384a0a2a6c2d_l3.png "Rendered by QuickLaTeX.com")
By contrast, if the cookie is disimilar to each muffin and the determinant is higher
![\[\det A(\{1,3\},\{1,3\}) = \det A(\{2,3\},\{2,3\}) = \det \twobytwo{10}{0}{0}{5} = 50.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-812d8318cba1d4a937e92858658ff7e8_l3.png "Rendered by QuickLaTeX.com")
Thus, even though the muffins are more popular overall, choosing our display case from a  -DPP, we have a
-DPP, we have a  chance of choosing a muffin and a cookie for our display case. It is for this reason that we can say that a -DPP preferentially selects for diverse items.
chance of choosing a muffin and a cookie for our display case. It is for this reason that we can say that a -DPP preferentially selects for diverse items.
Is sampling from a -DPP the best way of picking items for my display case? How does it compare to other possible methods?6Another method I’m partial to for this task is randomly pivoted Cholesky sampling, which is computationally cheaper than -DPP sampling even with the Markov chain sampling approach to -DPP sampling that we will discuss shortly. These are interesting questions for another time. For now, let us focus our attention on a different question: How would you sample from a -DPP?
Determinantal Point Process by Markov Chains
Sampling from a -DPP is a hard computational problem. Indeed, there are  possible -element subspaces of a set of items. The number of possibilities gets large fast. If I have
possible -element subspaces of a set of items. The number of possibilities gets large fast. If I have  items and want to pick
items and want to pick  of them, there are already over 10 trillion possible combinations.
of them, there are already over 10 trillion possible combinations.
Markov chains offer one compelling way of sampling a -DPP. First, we need a proposal distribution. Let’s choose the simplest one we can think of:
Proposal for
. To generate a proposal, choose a uniformly random element
out of
and a uniformly random element
out of
without
obtained from
).
Now, we need to compute the Metropolis–Hastings acceptance probability
![\[p_{\rm acc} = \min \left\{ 1 , \frac{\pi_{S'} T_{S'S}}{\pi_{S} T_{SS'}} \right\}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-5ff5280a20cfddd08b7917152edbfb68_l3.png "Rendered by QuickLaTeX.com")
For and which differ only by the addition of one element and the removal of another, the proposal probabilities  and
and  are both equal to
are both equal to  ,
,  . Using the formula for the probability of drawing from a -DPP, we compute that
. Using the formula for the probability of drawing from a -DPP, we compute that
![\[\frac{\pi_{S'}}{\pi_S} = \frac{\det A(S',S')}{\det A(S,S)}.\]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-26f4fdbc4d7624e49904e22703e8aaa7_l3.png "Rendered by QuickLaTeX.com")
Thus, the Metropolis–Hastings acceptance probability is just a ratio of determinants:
(Acc) ![\[p_{\rm acc} = \min \left\{ 1 , \frac{\pi_{S'} T_{S'S}}{\pi_{S} T_{SS'}} \right\} = \min \left\{ 1, \frac{\det A(S',S')}{\det A(S,S)} \right\}. \]](https://www.ethanepperly.com/wp-content/ql-cache/quicklatex.com-16c835576499e7fb3e6cf2c219732873_l3.png "Rendered by QuickLaTeX.com")
And we’re done. Let’s summarize our sampling algorithm:
- Choose an initial set
 arbitrarily and set .
arbitrarily and set . - Draw uniformly at random from
 .
. - Draw uniformly at random from
 .
. - Set
 .
. - With probability defined in (Acc), accept and set
 . Otherwise, set
. Otherwise, set  .
. - Set and go to step 2.
This is a remarkably simple algorithm to sample from a complicated distribution. And its fairly efficient as well. Analysis by Anari, Oveis Gharan, and Rezaei shows that, when you pick a good enough initial set , this sampling algorithm produces approximate samples from a -DPP in roughly  steps.7They actually use a slight variant of this algorithm where the acceptance probabilities (Acc) are reduced by a factor of two. Observe that this still has the correct stationary distribution because detailed balance continues to hold. The extra factor is introduced to ensure that the Markov chain is primitive. Remarkably, if is much smaller than , this Markov chain-based algorithm samples from a -DPP without even looking at all
steps.7They actually use a slight variant of this algorithm where the acceptance probabilities (Acc) are reduced by a factor of two. Observe that this still has the correct stationary distribution because detailed balance continues to hold. The extra factor is introduced to ensure that the Markov chain is primitive. Remarkably, if is much smaller than , this Markov chain-based algorithm samples from a -DPP without even looking at all  entries of the matrix !
entries of the matrix !
Upshot. Markov chains are a simple and general model for a state evolving randomly in time. Under mild conditions, Markov chains converge to a stationary distribution: In the limit of a large number of steps, the state of the system become randomly distributed in a way independent of how it was initialized. We can use Markov chains as algorithms to approximately sample from challenging distributions.
Great post. I especially enjoyed the fact that you used very different (and more interesting) practical examples than are used in most Markov chain teaching materials.
One thing that confused me a bit at first was the proof for detailed balance of the Metropolis Hastings update. When I realized that the equation is still for j≠i and the case for i=j follows from probabilities summing up to 1, it all made sense.
Thanks for the feedback! I’ve edited the post to hopefully be more clear.